Hierarchical Reasoning Model — 뇌에서 영감받은 계층적 잠재 추론 아키텍처
논문: Hierarchical Reasoning Model
저자: Guan Wang, Jin Li, Yuhao Sun, Xing Chen, Changling Liu, Yue Wu, Meng Lu, Sen Song, Yasin Abbasi Yadkori (Sapient Intelligence, Singapore)
발표: arXiv:2506.21734v3 (cs.AI), 2025년 6월 26일 제출 · 2025년 8월 4일 개정
코드: github.com/sapientinc/HRM
핵심 키워드: latent reasoning, hierarchical convergence, one-step gradient, deep supervision, adaptive computation time, ARC-AGI, brain-inspired
핵심 요약
HRM(Hierarchical Reasoning Model) 은 인간 뇌의 계층적·다중 시간척도(multi-timescale) 처리에서 영감을 받은 순환(recurrent) 아키텍처입니다. 표준 Transformer가 깊이가 고정되어 알고리즘적 추론에 한계를 보이고, Chain-of-Thought(CoT)가 취약한 분해·대량 데이터·높은 지연에 시달리는 문제를 정면으로 겨냥합니다.
핵심 아이디어는 서로 다른 속도로 도는 두 개의 결합된 순환 모듈입니다 — 느리고 추상적인 계획을 담당하는 고수준(H) 모듈과, 빠르고 세밀한 계산을 담당하는 저수준(L) 모듈. 이들은 “hierarchical convergence(계층적 수렴)” 를 통해 단일 forward pass 안에서 거대한 유효 계산 깊이(effective computational depth) 를 만들어냅니다. 놀랍게도 단 2,700만(27M) 파라미터, 약 1,000개의 학습 예제, 그리고 사전학습도 CoT 라벨도 없이 복잡한 추론 과제를 풉니다.
| 구분 | 표준 Transformer / CoT LLM | HRM |
|---|---|---|
| 추론 위치 | 토큰 수준 언어(CoT)로 외부화 | 잠재 공간(latent space) 내부에서 수행 |
| 계산 깊이 | 고정 깊이($\mathsf{AC}^0 / \mathsf{TC}^0$) | 순환으로 $N\times T$ 유효 깊이 확보 |
| 학습 신호 | CoT 라벨 / RL 희소 보상 | dense gradient (deep supervision) |
| 그래디언트 | BPTT, $O(T)$ 메모리 | 1-step 근사, $O(1)$ 메모리 |
| 데이터 요구량 | 방대함 | 과제당 ~1,000 예제 |
| 파라미터 | 수십억~ | 27M |
헤드라인 벤치마크 (모두 ~1,000 train 예제, 27M 파라미터, 사전학습·CoT 없음):
| 벤치마크 | HRM | o3-mini-high | Claude 3.7 8K | DeepSeek R1 | Direct pred |
|---|---|---|---|---|---|
| ARC-AGI-1 (960 ex) | 40.3 | 34.5 | 21.2 | 15.8 | 21.0 |
| ARC-AGI-2 (1120 ex) | 5.0 | 3.0 | 1.3 | 0.9 | ~0 |
| Sudoku-Extreme 9×9 (1000 ex) | 55.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| Maze-Hard 30×30 (1000 ex) | 74.5 | 0.0 | 0.0 | 0.0 | 0.0 |

Figure 1. 좌: HRM은 뇌의 계층 처리·시간 분리에서 영감을 받아, 서로 다른 시간척도로 도는 두 순환망이 협력해 과제를 푼다. 우: 약 1,000개 예제만으로 ~27M HRM이 inductive 벤치마크(ARC-AGI)와 상징적 트리탐색 퍼즐(Sudoku-Extreme, Maze-Hard)에서 SOTA CoT 모델을 능가한다. CoT 모델은 Sudoku·Maze에서 완전히 0%로 실패한다. HRM은 무작위 초기화 상태에서 CoT 없이 입력으로부터 직접 답을 만든다.
1. 서론 — 깊이의 부재와 CoT의 한계
딥러닝은 이름 그대로 “층을 더 쌓는다”는 아이디어에서 출발했지만, 정작 대형 언어모델의 핵심 구조는 역설적으로 얕습니다(shallow). 표준 Transformer는 고정된 깊이 때문에 $\mathsf{AC}^0$나 $\mathsf{TC}^0$ 같은 계산 복잡도 클래스에 머물러, 다항 시간이 필요한 문제를 풀 수 없고 Turing-complete하지 않습니다. 저자들의 Sudoku 실험은 Transformer의 너비(width) 를 키워도 성능이 오르지 않고 오직 깊이(depth) 만이 중요함을 보여줍니다(Figure 2).
LLM은 이 한계를 CoT 프롬프팅으로 우회해 왔습니다. 그러나 저자들은 CoT가 해결책이 아니라 목발(crutch) 이라고 봅니다 — 인간이 정의한 취약한 분해에 의존해 한 단계만 어긋나도 전체 추론이 무너지고, 토큰 수준 패턴에 추론을 묶어두며, 막대한 데이터와 토큰 생성으로 느립니다.
대안은 잠재 추론(latent reasoning) — 모델이 내부 은닉 상태 공간에서 계산을 수행하는 것입니다. 언어는 사고의 기반이 아니라 소통의 도구이며, 뇌는 언어로 끊임없이 번역하지 않고도 잠재 공간에서 길고 일관된 추론을 효율적으로 유지합니다. 하지만 잠재 추론의 힘은 결국 모델의 유효 계산 깊이에 좌우되는데, 단순히 층을 쌓으면 기울기 소실로 학습이 불안정해지고, 순환망은 조기 수렴(early convergence) 과 생물학적으로 비현실적이고 메모리 비싼 BPTT 에 시달립니다.
뇌는 이 난제의 청사진을 제공합니다 — 서로 다른 시간척도로 동작하는 피질 영역들의 계층으로 계산을 조직하고, 순환 피드백으로 표현을 반복 정제하며(느린 상위 영역이 유도, 빠른 하위 회로가 실행), BPTT의 막대한 credit-assignment 비용 없이 깊이를 달성합니다.
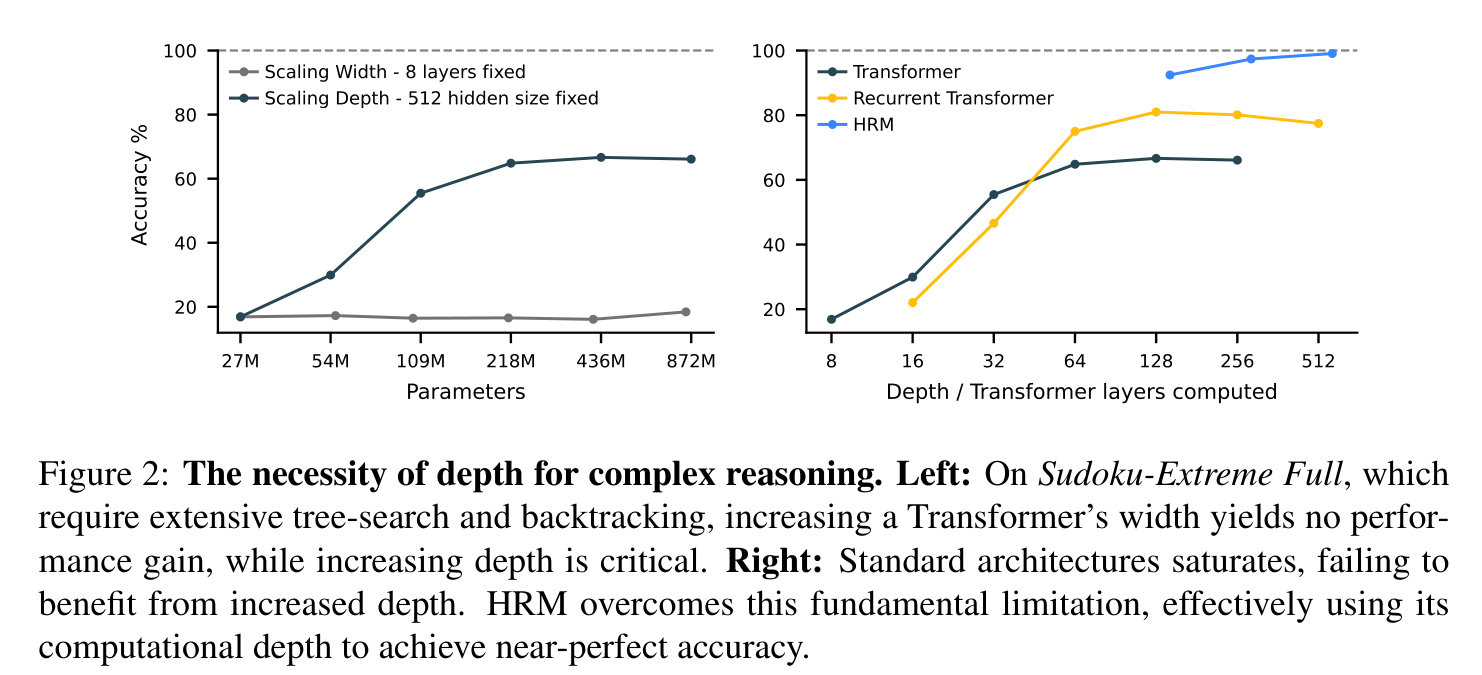
Figure 2. 좌: Sudoku-Extreme-Full에서 Transformer의 너비를 키워도(파라미터 27M→872M) 성능이 정체되는 반면, 깊이는 결정적이다. 우: 표준 구조(Transformer, Recurrent Transformer)는 깊이를 늘려도 포화되지만, HRM은 계산 깊이를 효과적으로 활용해 거의 완벽한 정확도에 도달한다.
2. HRM 구조
HRM은 뇌에서 관찰되는 세 가지 신경 계산 원리에 기반합니다.
- 계층적 처리(Hierarchical processing): 상위 피질 영역은 더 긴 시간척도로 정보를 통합해 추상 표현을 형성하고, 하위 영역은 즉각적·세밀한 처리를 담당.
- 시간 분리(Temporal separation): 계층은 서로 다른 고유 리듬으로 동작(느린 theta파 4–8 Hz, 빠른 gamma파 30–100 Hz). 안정적 상위 유도 + 빠른 하위 계산.
- 순환 연결(Recurrent connectivity): 광범위한 피드백 루프로 반복 정제, BPTT 없이 깊은 credit assignment 회피.
2.1 네 가지 구성요소와 동역학
HRM은 4개의 학습 가능한 구성요소로 이뤄집니다 — 입력망 $f_I$, 저수준 순환모듈 $f_L$, 고수준 순환모듈 $f_H$, 출력망 $f_O$. 한 번의 forward pass는 $N$개의 고수준 cycle로 구성되며, 각 cycle은 $T$개의 저수준 timestep을 가집니다(총 $N\times T$ step).
입력 $x$는 먼저 작업 표현 $\tilde{x} = f_I(x;\theta_I)$로 투영됩니다. 각 timestep $i$에서 L 모듈은 매 step 갱신되지만(자기 이전 상태 + 고정된 H 상태 + 입력), H 모듈은 cycle당 1회($T$ step마다) L의 최종 상태로 갱신됩니다.
\[z_L^{i} = f_L\!\left(z_L^{i-1},\, z_H^{i-1},\, \tilde{x};\, \theta_L\right)\] \[z_H^{i} = \begin{cases} f_H\!\left(z_H^{i-1},\, z_L^{i-1};\, \theta_H\right) & \text{if } i \equiv 0 \pmod{T} \\[4pt] z_H^{i-1} & \text{otherwise} \end{cases}\]$N$ cycle 후 H 상태에서 예측을 추출합니다: $\hat{y} = f_O(z_H^{NT};\theta_O)$. 이후 halting 메커니즘(§3.3)이 종료할지, 추가 forward pass를 돌릴지 결정합니다.
2.2 Hierarchical Convergence — 조기 수렴 탈출
표준 RNN의 근본 한계는 너무 빨리 수렴한다는 것입니다. 은닉 상태가 고정점에 가까워지면 갱신 폭이 줄어 이후 계산이 사실상 멈추고, 유효 깊이가 제한됩니다. HRM은 이를 hierarchical convergence로 해결합니다.
- 각 cycle 안에서 L 모듈(RNN)은 주어진 $z_H$에 의존하는 local equilibrium까지 안정적으로 수렴.
- $T$ step 후 H 모듈이 그 하위 계산 결과($z_L$의 최종 상태)를 받아 자신을 갱신.
- 이 $z_H$ 갱신이 L에게 새로운 컨텍스트를 부여해 계산 경로를 “리셋”하고, 다른 local equilibrium을 향한 새 수렴 단계를 시작.
이렇게 구분되고 안정적인 nested 계산의 연속이 가능해져, 표준 RNN이 $T$ 안에 수렴해버리는 것과 달리 유효 깊이 $N\times T$ 를 누립니다.
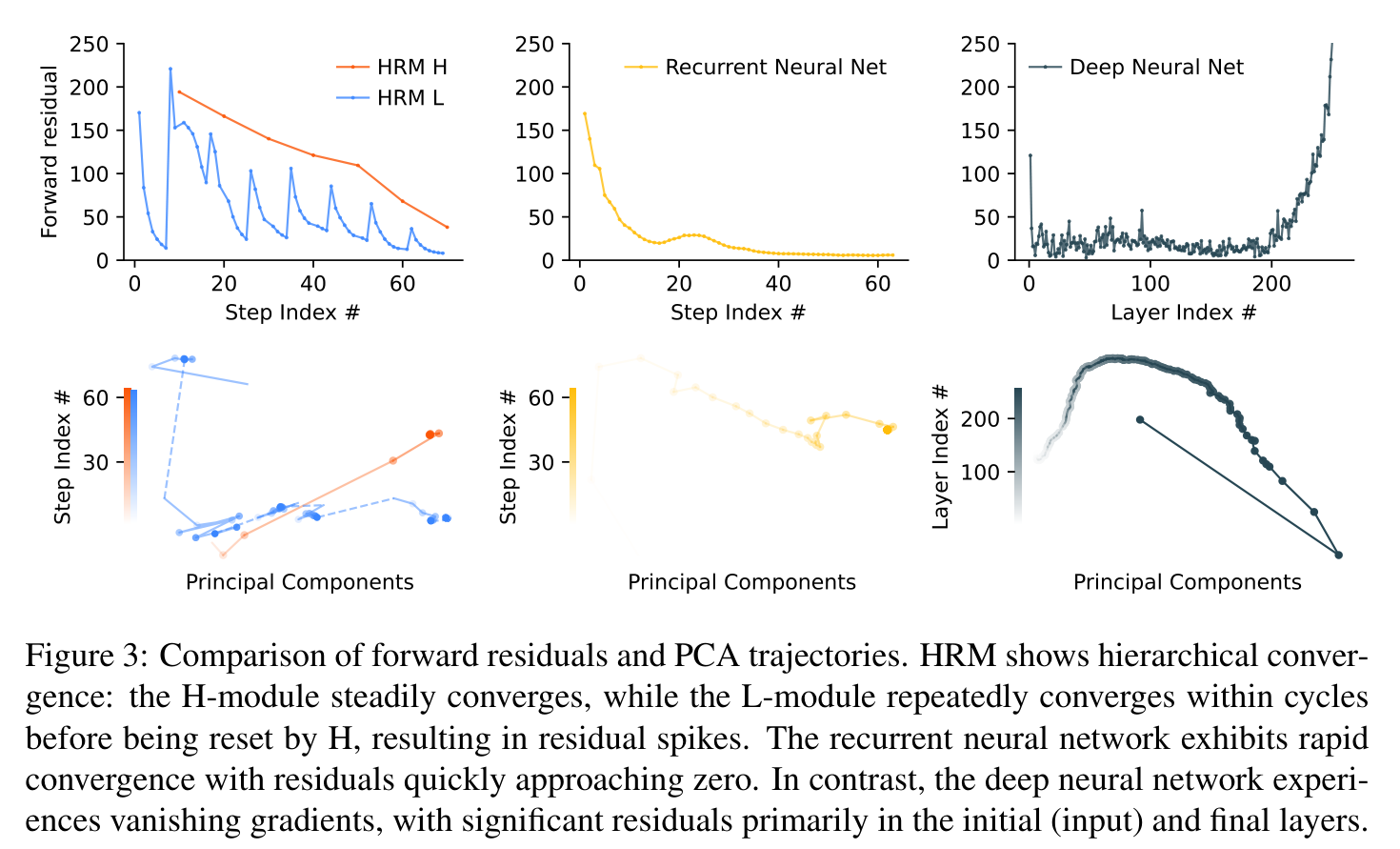
Figure 3. HRM은 계층적 수렴을 보인다 — H 모듈은 꾸준히 수렴하고, L 모듈은 cycle 내에서 반복 수렴 후 H에 의해 리셋되며 residual 스파이크를 만든다. 일반 RNN은 residual이 빠르게 0으로 떨어지는 급속 수렴을, 심층 신경망은 기울기 소실(초기·최종 층에만 유의미한 residual)을 보인다. HRM만이 많은 step에 걸쳐 높은 계산 활동을 유지하면서도 안정적으로 수렴한다.
3. 학습 방법
3.1 One-Step Gradient Approximation — BPTT 없이 $O(1)$ 메모리
순환망은 보통 BPTT로 그래디언트를 구하지만, 이는 $T$ step의 은닉 상태를 모두 저장해야 해 $O(T)$ 메모리를 요구하고 배치 크기를 제한하며 생물학적으로도 비현실적입니다. HRM은 각 모듈의 마지막 상태의 그래디언트만 사용하고 나머지는 상수로 취급하는 1-step 근사를 제안합니다. 그래디언트 경로는:
출력 head → H 모듈 최종 상태 → L 모듈 최종 상태 → 입력 임베딩
이 방법은 $O(1)$ 메모리로, time을 unroll할 필요 없이 PyTorch autograd로 간단히 구현됩니다(Figure 4). 이론적 근거는 Deep Equilibrium Model(DEQ) 의 수학 — Implicit Function Theorem(IFT) 으로 BPTT를 우회합니다. 고정점 $z_H^\star = F(z_H^\star;\tilde{x},\theta)$에서 정확한 그래디언트는 $(I - J_F)^{-1}$를 포함하지만, Neumann 급수
\[(I - J_F)^{-1} = I + J_F + J_F^2 + J_F^3 + \cdots\]의 1차항만 취해 $(I - J_F)^{-1} \approx I$로 근사하면 행렬 역연산 없이 그래디언트를 얻습니다. 이는 피질의 credit assignment가 전역 재생(replay)이 아니라 단거리·시간적으로 국소적인 메커니즘에 의존한다는 관점과도 부합합니다.
3.2 Deep Supervision
뇌의 주기적 신경 진동이 학습 시점을 조절한다는 원리에서 영감을 받아, HRM은 deep supervision을 도입합니다. 한 데이터 $(x,y)$에 대해 여러 번의 forward pass(각각을 segment라 부름)를 돌리고, 각 segment $m$마다:
- 이전 상태 $z^{m-1}$로부터 $(z^m, \hat{y}^m) \leftarrow \mathrm{HRM}(z^{m-1}, x; \theta)$ 계산,
- 손실 $L^m \leftarrow \mathrm{LOSS}(\hat{y}^m, y)$,
- 파라미터 갱신 $\theta \leftarrow \mathrm{OptStep}(\theta, \nabla_\theta L^m)$.
핵심은 다음 segment의 입력으로 넘기기 전에 은닉 상태 $z^m$을 detach(계산 그래프에서 분리)한다는 점입니다. 따라서 segment $m+1$의 그래디언트가 $m$으로 역전파되지 않아, 재귀적 deep supervision에 대한 1-step 근사가 됩니다. 이는 H 모듈에 더 빈번한 피드백을 주고 정규화 효과를 내며, 복잡한 Jacobian 기반 기법보다 우수한 안정성을 보입니다.

Figure 4. 상: 근사 그래디언트를 적용한 HRM 다이어그램 — 파란색은 그래디언트가 흐르는(Requires Grad) 마지막 L·H 갱신, 검은색은
no_grad구간. 하: deep supervision 학습의 PyTorch 의사코드 —with torch.no_grad()로 $N T-1$ step을 돌린 뒤 마지막 1 step만 그래디언트를 계산하고, segment 간z = z.detach()로 분리한다.
3.3 Adaptive Computation Time (ACT) — “Thinking, Fast and Slow”
뇌는 자동적 사고(System 1)와 숙고적 추론(System 2)을 동적으로 오갑니다. HRM은 Q-learning 기반 적응적 halting으로 이를 모방합니다. Q-head가 H 모듈의 최종 상태로 halt/continue 두 행동의 Q값을 예측합니다:
최대 segment 수 $M_{max}$(고정 하이퍼파라미터)와 최소 $M_{min}$(확률적 변수: 확률 $\varepsilon$로 ${2,\dots,M_{max}}$에서 균등 샘플링해 더 오래 생각하도록 유도)로 제어됩니다. halt는 segment가 $M_{max}$를 넘거나, $\hat{Q}{halt} > \hat{Q}{continue}$이고 $M_{min}$에 도달했을 때 선택됩니다. Q-learning target은:
전체 손실은 시퀀스 손실과 Q-head 손실의 결합입니다:
\[L^m_{ACT} = \mathrm{LOSS}(\hat{y}^m, y) + \mathrm{BCE}(\hat{Q}^m, \hat{G}^m)\]안정성: 깊은 Q-learning은 보통 replay buffer·target network가 필요하지만 HRM은 이를 쓰지 않습니다. 대신 Post-Norm 구조 + RMSNorm + AdamW(파라미터를 $1/\lambda$로 유계화)로 안정적 수렴 조건을 만족합니다.
3.4 Inference-time Scaling
ACT의 또 다른 이점은 추론 시점 스케일링입니다 — 재학습이나 구조 변경 없이 단지 $M_{max}$만 키우면 성능이 향상됩니다. 깊은 추론이 필요한 Sudoku에서는 큰 이득, 반면 보통 몇 번의 변환으로 풀리는 ARC-AGI에서는 이득이 미미합니다.
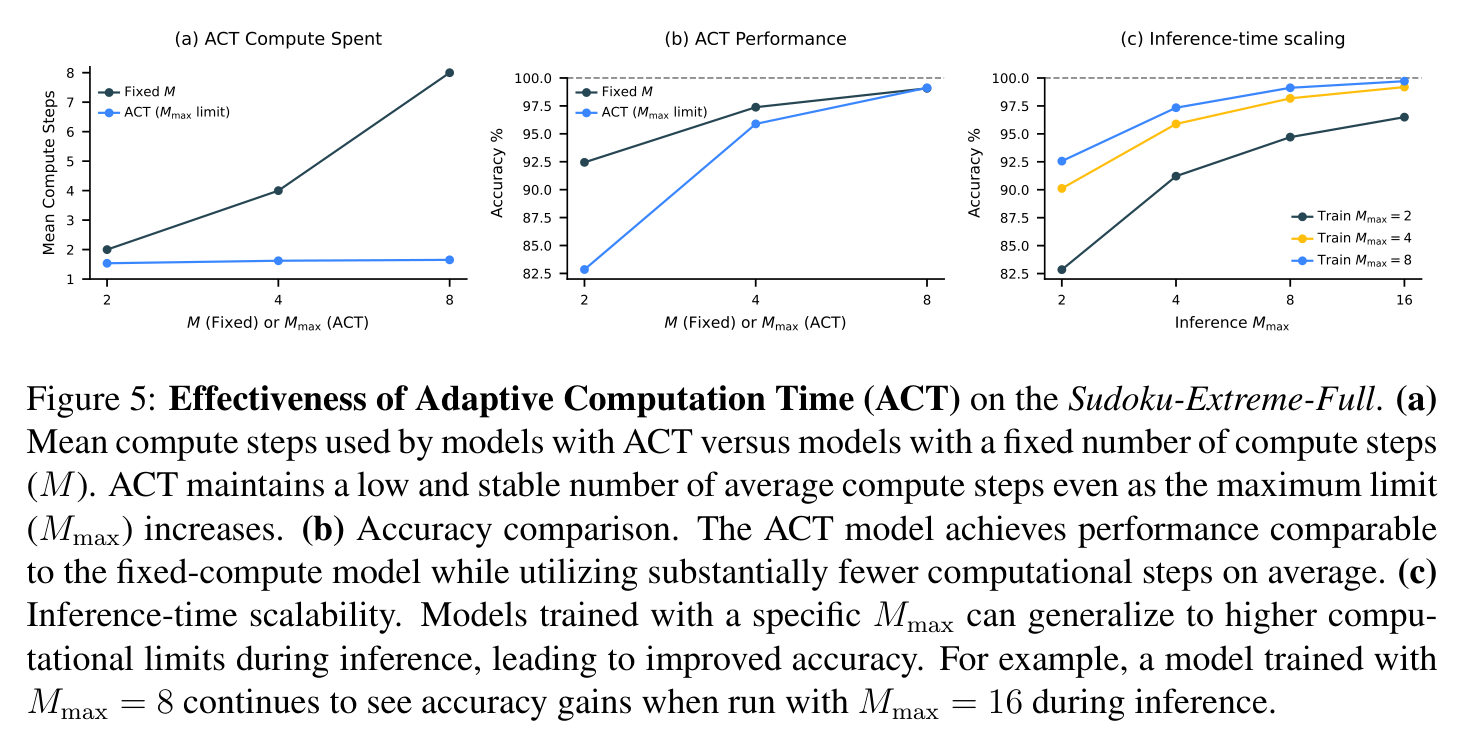
Figure 5. (a) ACT는 최대 한도 $M_{max}$가 커져도 평균 compute step을 낮고 안정적으로 유지한다. (b) ACT 모델은 고정 compute 모델과 동등한 정확도를 훨씬 적은 평균 step으로 달성한다. (c) 특정 $M_{max}$로 학습한 모델이 추론 시 더 큰 한도로 일반화 — 예컨대 $M_{max}=8$로 학습한 모델을 추론 시 $M_{max}=16$으로 돌리면 정확도가 계속 향상된다.
4. 실험 결과
4.1 벤치마크
- ARC-AGI Challenge: IQ 테스트형 귀납 추론. 2–3개 입출력 데모로 추상 규칙을 추출해 새 입력에 적용(두 번의 시도 허용). ARC-AGI-2는 더 깊은 합성적 추론·다단계 논리·상징적 추상화를 요구.
- Sudoku-Extreme: 9×9 논리 퍼즐. 기존 데이터셋(Kaggle, 17-clue)은 단순 기법으로 풀려 쉬움. 본 데이터셋은 평균 22 backtracks(tdoku 솔버 기준)로, 최근 Sudoku-Bench의 0.45보다 훨씬 어려움. 분석 실험용 Sudoku-Extreme-Full은 383만 예제.
- Maze-Hard: 30×30 미로 최단경로 탐색. 최단경로 길이 >110 인 어려운 인스턴스만 필터링. 유효하고 최적인 경로만 정답.
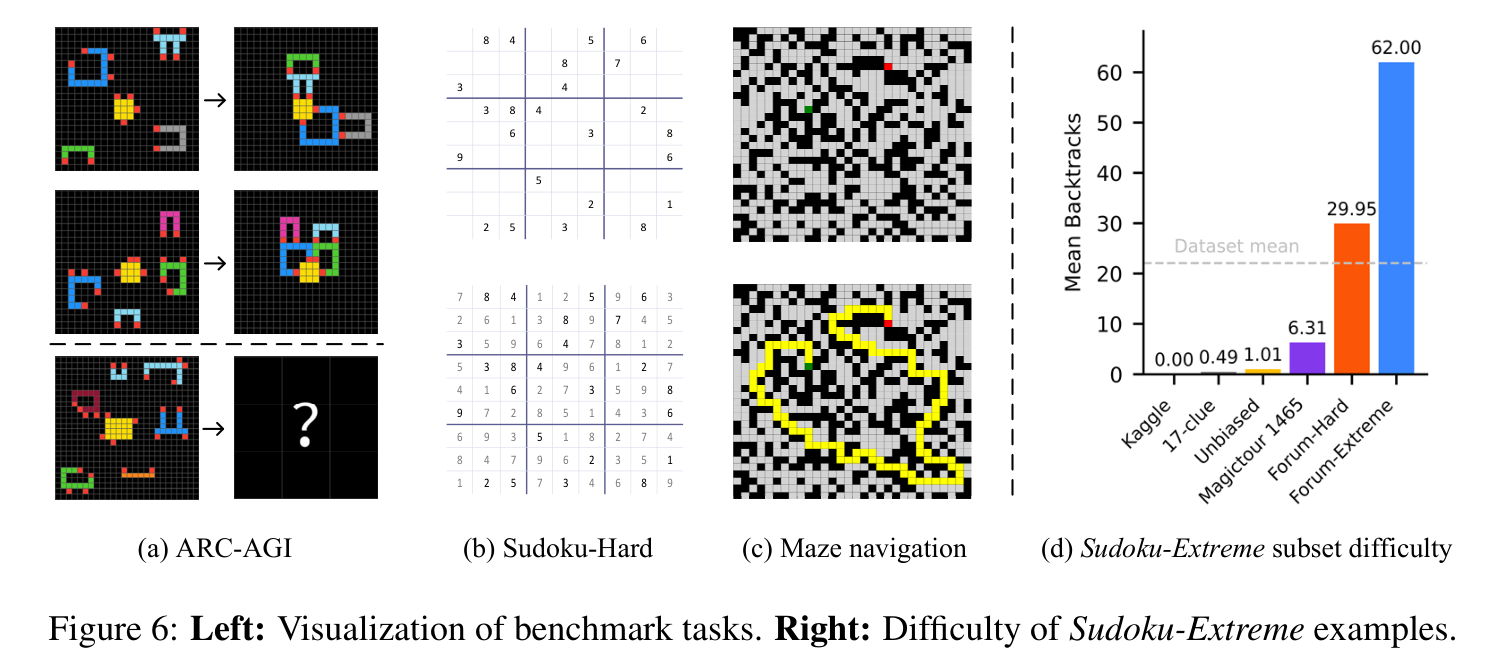
Figure 6. 좌: 세 벤치마크 과제의 시각화 — (a) ARC-AGI 격자 변환, (b) Sudoku, (c) Maze 내비게이션. 우: (d) Sudoku-Extreme 부분집합들의 난도(backtrack 수) — Sudoku-Extreme은 평균 22로 기존 데이터셋보다 월등히 어렵다.
4.2 결과 해석
모든 벤치마크에서 HRM은 무작위 초기화 후 ~1,000 입출력 쌍, 사전학습·CoT 라벨 없이 학습됩니다.
- ARC-AGI: HRM(27M, 900토큰 컨텍스트)이 40.3% 로 o3-mini-high(34.5%)·Claude 3.7 8K(21.2%)를 능가. “Direct pred”(동일 설정에 Transformer만 교체)는 ARC-AGI-1에서 Liao & Gu의 도메인 특화 등변망 수준(~21%)에 그쳐, HRM 구조 + ACT로 2배 이상 향상.
- Sudoku-Extreme · Maze-Hard: CoT 기반 모델은 모두 0%로 완전 실패(긴 추론 트레이스가 필요한 과제에 특히 취약). 1,000 예제 기준 “Direct pred”(8-layer Transformer)도 완전 실패하고, 더 큰 Sudoku-Extreme-Full로 학습해도 16.9%에 그침. (참고: Lehnert et al.의 175M Transformer는 100만 예제로도 30×30 Maze에서 pass@64 < 20%.)
5. HRM은 어떻게 추론하는가 — 중간 timestep 시각화
HRM이 어떤 알고리즘을 학습했는지 들여다보기 위해, 각 timestep에서 H 모듈을 예비 forward 통과시켜 디코딩한 중간 예측 $\bar{y}^i$를 시각화했습니다(Figure 7).
- Maze: 처음에 여러 경로를 동시에 탐색 → 막히거나 비효율적인 경로 제거 → 대략적 윤곽 구성 → 여러 번 정제.
- Sudoku: 깊이 우선 탐색(DFS) 과 유사 — 잠재 해를 탐색하다 막다른 길에서 백트래킹.
- ARC: 보드를 점진적으로 조정하며 개선하는 hill-climbing식 진행(Sudoku 같은 잦은 백트래킹 없음).
즉 HRM은 과제마다 다른 추론 전략을 적응적으로 채택합니다.

Figure 7. HRM의 timestep별 중간 예측. 상(Maze-Hard): 파란 셀이 예측 경로. 중(Sudoku-Extreme): 굵은 셀은 초기 주어진 값, 빨강은 제약 위반 셀, 회색 음영은 이전 timestep 대비 변경. 하(ARC-AGI-2): 좌측은 예시 입출력 쌍, 우측은 테스트 입력을 푸는 중간 단계들.
6. 뇌와의 대응 (Brain Correspondence)
시스템 신경과학의 한 원리는 뇌 영역의 기능적 다재다능함이 신경 표현의 차원성(dimensionality)과 연결된다는 것입니다. 상위 피질 영역일수록 더 높은 차원의 상태공간 궤적을 가집니다. 이를 정량화하는 Participation Ratio(PR) 는 신경 궤적 공분산 행렬의 고유값 ${\lambda_i}$로:
\[\mathrm{PR} = \frac{\left(\sum_i \lambda_i\right)^2}{\sum_i \lambda_i^2}\]PR이 높을수록 분산이 여러 차원에 고르게 퍼져(고차원), 낮을수록 소수 주성분에 집중(저차원)됩니다.
저자들이 Sudoku-Extreme-Full로 학습한 HRM의 PR을 측정한 결과는 생물학적 발견과 놀랍도록 평행합니다.
| 모듈 | 학습된 HRM | 미학습(랜덤) HRM |
|---|---|---|
| 저수준 $z_L$ | PR = 30.22 | 42.09 |
| 고수준 $z_H$ | PR = 89.95 | 40.75 |
| 비율 $z_H/z_L$ | ≈ 2.98 | ≈ 1.0 (분리 없음) |
학습된 모델은 명확한 차원 계층을 보이며($z_H$가 훨씬 고차원), 과제(궤적) 수를 10→100으로 늘리면 $z_H$ 차원은 함께 증가하지만 $z_L$은 안정적입니다. 반면 미학습 모델은 두 모듈이 거의 동일해 계층이 없습니다 → 이 차원 계층은 구조의 산물이 아니라 학습으로 창발하는 성질입니다.
주목할 점은 HRM의 $z_H/z_L \approx 2.98$ 비율이 쥐 대뇌피질의 ≈ 2.25 와 가깝다는 것입니다(쥐 피질은 하위 감각영역→상위 연합영역으로 PR이 단조 증가, Spearman $\rho = 0.79$, $P = 0.0003$). 또한 일반적인 심층망이 neural collapse(마지막 층 특징이 저차원으로 붕괴)를 보이는 것과 달리, HRM은 상위 모듈에서 고차원 표현을 유지합니다 — 이는 전전두피질(PFC) 같은 고차 뇌영역의 인지적 유연성의 특징입니다. (단, 저자들은 이 증거가 상관적이며 인과성은 향후 과제로 남는다고 명시합니다.)
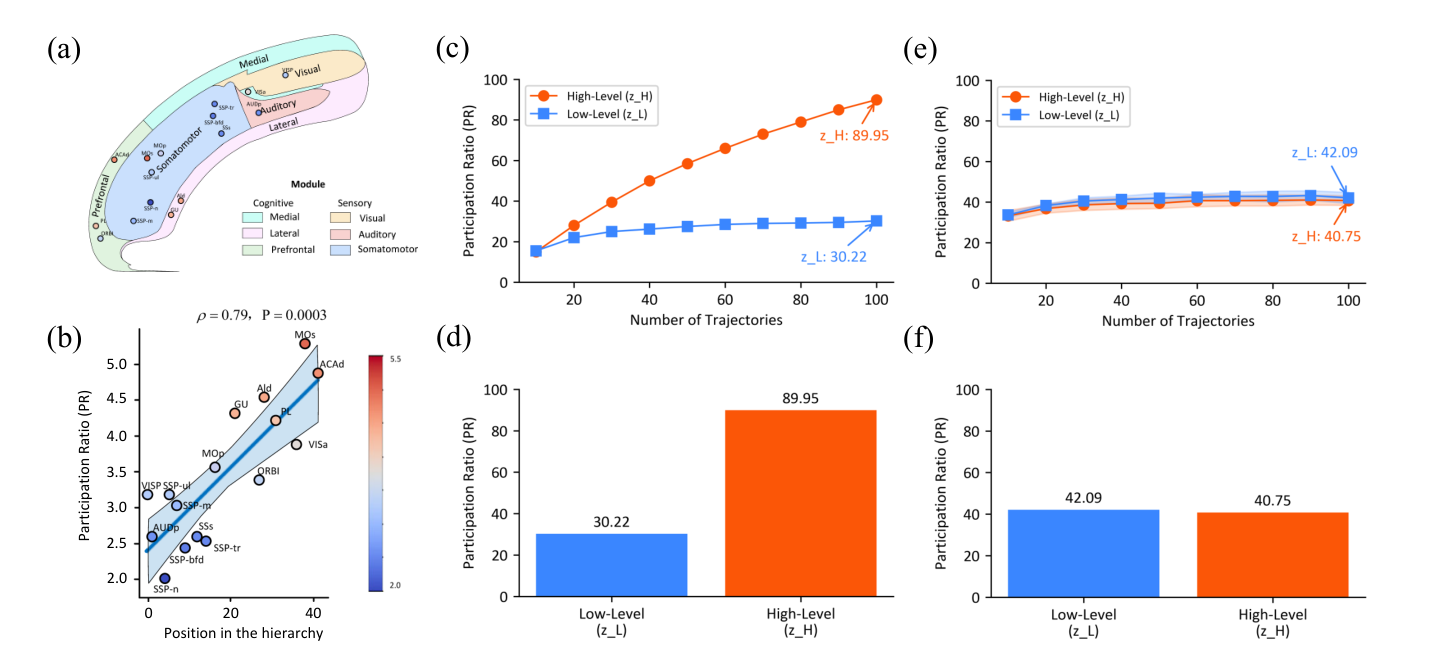
Figure 8. HRM과 쥐 피질의 계층적 차원성. (a,b) 쥐 피질 — 계층 위치가 높을수록 PR 증가($\rho=0.79$). (c,d) 학습된 HRM — $z_H$(PR=89.95)가 $z_L$(PR=30.22)보다 훨씬 고차원이고, 과제 수가 늘면 $z_H$ 차원이 확장. (e,f) 미학습 HRM — 두 모듈 PR이 42.09 vs 40.75로 거의 같아 계층 분리 없음. 차원 계층이 학습으로 창발함을 확인.
7. 논의
- Turing-completeness: Universal Transformer처럼 HRM도 충분한 메모리·시간이 주어지면 계산적으로 보편적(어떤 튜링 기계도 시뮬레이션 가능)입니다. 표준 Transformer의 고정 깊이 한계를 넘어서며, 조기 수렴·BPTT 문제를 해결하고 적응적 계산을 갖춰 실질적 Turing-completeness에 다가갑니다.
- RL + CoT 대비: 최근 증거는 RL이 새로운 추론 메커니즘을 발견하기보다 기존 CoT 능력을 발현시킬 뿐이며 불안정·데이터 비효율적임을 시사합니다. HRM은 희소 보상 대신 dense gradient 감독을 받고, 연속 공간에서 동작해 토큰마다 동일한 계산을 할당하지 않습니다.
- Linear attention: 순환은 Transformer의 $O(n^2)$ 어텐션을 대체하는 효율적 수단으로도 탐구됐습니다(예: Log-linear Attention). 다만 어텐션만 바꿔서는 고정 깊이 문제가 해결되지 않아 여전히 CoT가 필요합니다.
관련 연구로는 Neural Turing Machine·DNC·Neural GPU·Recurrent Relational Network, Universal Transformer, PonderNet(적응적 halting), 그리고 뇌영감 모델 Spaun·Tolman-Eichenbaum Machine 등이 있으나, 이들은 단순 추론에 국한되거나 수작업 알고리즘에 의존하는 한계가 있습니다.
8. 결론 및 의의
HRM은 계층 구조와 다중 시간척도 처리로 학습 안정성·효율을 해치지 않으면서 거대한 계산 깊이를 달성하는 뇌영감 아키텍처입니다. 27M 파라미터·1,000 예제만으로 ARC·Sudoku·Maze 등 현대 LLM과 CoT가 어려워하는 과제를 효과적으로 풉니다. 뇌의 계층 구조가 인지의 핵심임에도 AI는 여전히 비계층적 모델을 선호해 왔는데, HRM은 이 패러다임에 도전하며 CoT 추론의 실질적 대안이자 Turing-complete 보편 계산을 향한 기반 프레임워크의 가능성을 제시합니다.
부록 — 핵심 수식 정리
① Forward 동역학 (L은 매 step, H는 cycle당 1회):
\[z_L^{i} = f_L\!\left(z_L^{i-1}, z_H^{i-1}, \tilde{x}; \theta_L\right), \qquad z_H^{i} = \begin{cases} f_H\!\left(z_H^{i-1}, z_L^{i-1}; \theta_H\right) & i \equiv 0 \pmod{T} \\ z_H^{i-1} & \text{otherwise} \end{cases}\]② IFT 기반 정확한 그래디언트 (고정점 $z_H^\star$, $J_F = \partial F / \partial z_H$):
\[\frac{\partial z_H^\star}{\partial \theta} = \left(I - J_F\right)^{-1} \left.\frac{\partial F}{\partial \theta}\right|_{z_H^\star}\]③ 1-step 근사 ($(I-J_F)^{-1}\approx I$):
\[\frac{\partial z_H^\star}{\partial \theta_H} \approx \frac{\partial f_H}{\partial \theta_H}, \quad \frac{\partial z_H^\star}{\partial \theta_L} \approx \frac{\partial f_H}{\partial z_L^\star}\cdot\frac{\partial z_L^\star}{\partial \theta_L}, \quad \frac{\partial z_H^\star}{\partial \theta_I} \approx \frac{\partial f_H}{\partial z_L^\star}\cdot\frac{\partial z_L^\star}{\partial \theta_I}\]④ ACT 손실 및 Q-learning target:
\[L^m_{ACT} = \mathrm{LOSS}(\hat{y}^m, y) + \mathrm{BCE}(\hat{Q}^m, \hat{G}^m)\]⑤ Participation Ratio (effective dimensionality):
\[\mathrm{PR} = \frac{\left(\sum_i \lambda_i\right)^2}{\sum_i \lambda_i^2}\]한 줄 정리
“깊이를 언어(CoT)가 아니라 구조로 만든다.” — 빠른 L 모듈과 느린 H 모듈이 hierarchical convergence로 단일 forward pass에서 유효 깊이 $N\times T$를 만들고, BPTT 없는 1-step 그래디언트($O(1)$ 메모리)·deep supervision·ACT로 학습하여, 27M 파라미터·1,000 예제·CoT 없이 Sudoku·Maze·ARC를 푼다. 게다가 학습으로 뇌 피질과 유사한 차원 계층이 창발한다.
References
- Wang, Li, Sun, Chen, Liu, Wu, Lu, Song, Abbasi-Yadkori. Hierarchical Reasoning Model. arXiv:2506.21734 (2025). — 본 논문 · 코드
- Bai, Kolter, Koltun. Deep Equilibrium Models. (2019) — 1-step gradient의 이론적 기반(IFT)
- Chollet. On the Measure of Intelligence / ARC-AGI — 귀납 추론 벤치마크
- Lehnert et al. Searchformer (2024) — Maze 생성 절차·Transformer baseline
- Graves. Adaptive Computation Time for RNNs (2016); Banino et al. PonderNet (2021) — 적응적 halting
- Dehghani et al. Universal Transformers (2019) — 순환 루프 + halting, Turing-completeness
- Posani et al. — 쥐 피질 Participation Ratio·차원 계층 (Figure 8 a,b)
- Gallici et al. (2024) — 정규화 하의 Q-learning 수렴 이론