Hallucinations Undermine Trust; Metacognition is a Way Forward — Faithful Uncertainty로 환각을 재정의하다
논문: Hallucinations Undermine Trust; Metacognition is a Way Forward
저자: Gal Yona, Mor Geva, Yossi Matias (Google Research, Tel Aviv University)
발표: arXiv:2605.01428v1 (cs.CL), 2026년 5월 2일 · ICML 2026 Position Track
핵심 키워드: hallucination, confident error, faithful uncertainty, calibration vs discrimination, metacognition, utility tax, agentic control layer
핵심 요약
이 논문은 LLM의 환각(hallucination) 을 바라보는 프레임 자체를 바꾸자고 제안하는 포지션 페이퍼입니다. 저자들의 진단은 이렇습니다 — 지금까지의 사실성(factuality) 향상은 대부분 모델의 지식 경계(knowledge boundary)를 넓히는 것(더 많은 사실을 인코딩)이었지, 그 경계를 스스로 인식하는 능력(아는 것과 모르는 것을 구분)을 키운 것이 아니었습니다. 그런데 후자는 본질적으로 어렵습니다. 모델은 calibration(평균 정답률을 맞히는 능력)은 갖췄지만 discrimination(어떤 답이 틀렸는지 콕 집어내는 능력)이 부족하기 때문입니다. 이 discrimination gap 때문에 “환각 = 모든 오류”라는 전통적 관점에서는 신뢰성과 유용성의 교환(utility-factuality trade-off) 이 불가피해집니다.
저자들의 해법은 환각을 단순 오류가 아니라 “confident error(적절한 한정 없이 자신만만하게 전달된 틀린 정보)” 로 재정의하는 것입니다. 그러면 “답하거나(answer) 기권하거나(abstain)”라는 이분법을 넘어서는 제3의 길 — 불확실성을 표현하기가 열립니다. 핵심 개념이 바로 Faithful Uncertainty(충실한 불확실성): 모델이 말로 표현하는 확신(linguistic uncertainty) 을 내부의 실제 확신(intrinsic uncertainty) 에 정렬시키는 것입니다.
| 구분 | 전통적 관점 (Hallucination = 모든 오류) | 본 논문 (Hallucination = Confident Error) |
|---|---|---|
| 목표 | 환각을 완전히 제거 | 아는 만큼 답하되 남은 불확실성을 충실히 표현 |
| 선택지 | answer or abstain (이분법) | answer · abstain · express uncertainty (제3의 길) |
| 정렬 대상 | 모델 출력 ↔ 외부 세계의 진실 (사실상 불가능) | 모델 출력 ↔ 내부 상태 (closed-loop, 풀 수 있음) |
| 보장 단위 | calibration = 집계(aggregate) 속성 | faithfulness = instance-level 보장 |
| 틀린 답의 운명 | 신뢰를 무너뜨리는 환각 | 적절히 한정되면 “유용한 가설(hypothesis)” 로 전환 |
| 에이전트에서의 역할 | — | 도구 사용을 다스리는 control layer |
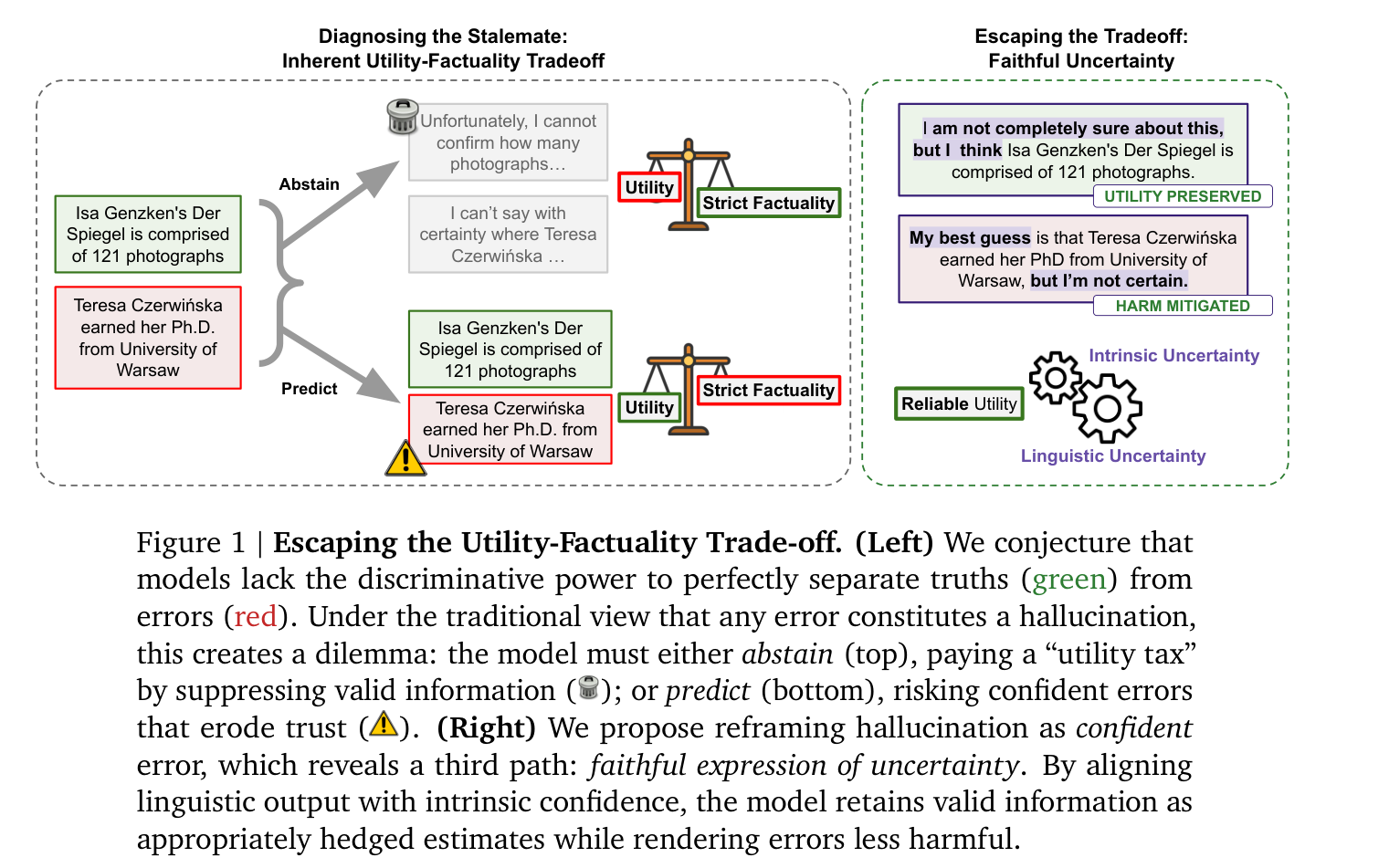
Figure 1. (왼쪽) 교착 상태의 진단. 모델은 진실(초록)과 오류(빨강)를 완벽히 분리할 discriminative power가 부족하다. “모든 오류가 환각”이라는 전통적 관점에서는 딜레마가 생긴다 — 기권하면(위) 유효한 정보까지 억눌러 “utility tax(유용성 세금)” 를 내고, 예측하면(아래) confident error로 신뢰를 잃는다. (오른쪽) 교착에서 벗어나기. 환각을 confident error로 재정의하면 제3의 길이 보인다 — 출력의 언어적 확신을 내부 확신에 정렬시키면, 유효한 정보는 적절히 한정된 추정치로 보존되고 오류는 덜 해롭게 된다.
1. 서론 — 환각은 왜 사라지지 않는가
사실성 연구의 큰 진전에도 불구하고, 프런티어 모델조차 가장 단순한 설정 — 명확한 정답이 있는 사실형 질의응답(factoid QA) 에서도 여전히 환각을 일으킵니다. 더구나 이런 오류는 권위 있는 어조로 전달되어 사용자 신뢰를 무너뜨리고 잘못된 정보를 퍼뜨립니다.
저자들의 첫 번째 주장은 비대칭성입니다.
- 지식 경계 확장 (encoding more facts): 스케일·데이터·학습 레시피 개선으로 달성 가능.
- 경계 인식 (distinguishing known from unknown): 모델이 진실과 오류를 완벽히 구분할 discriminative power 자체가 부족해 본질적으로 어려움.
불확실성 정량화(uncertainty quantification) 연구는 현대 LLM에서 잘 보정된(well-calibrated) 신뢰도 신호를 뽑아낼 수 있음을 보였지만, calibration이 discrimination을 보장하지는 않습니다. 전통적 관점(“환각 = 오류”)에서 discrimination이 부족하면, 환각을 0으로 만들려면 불확실할 때마다 기권해야 하고 그러면 유효한 정보까지 버려집니다. 모델 제공자들은 이 utility tax를 내고 싶어 하지 않기에, 결국 답을 우선하고 여전히 환각하는 모델이 나옵니다 (Figure 1 왼쪽).
이 관점은 최근의 여러 경험적 관찰을 하나로 묶습니다.
- Truthfulness probe의 빈약한 일반화 와 confident hallucination(높은 내부 확신을 가진 사실 오류) 의 존재 → 모델 내부 표현만으로 진위를 예측하는 데 한계.
- 모델이 의도적 안전 위반은 “자백(confess)”하도록 정렬되지만, 그 능력이 환각에는 전이되지 않음 → 강한 감독으로도 메우지 못하는 결함.
- “thinking(확장된 추론)”이 오히려 환각을 늘리고 abstention을 악화시킴 → 현재 학습이 trade-off 상황에서 유용성 쪽으로 기울도록 유도함을 시사.
그러나 confident error로 재정의하면 이 교착이 풀립니다. 적절한 한정과 함께 전달된 오류는 환각이 아니라, 검토를 위해 제시된 가설입니다. 단, 무조건 더 한정(hedge)하는 것은 답이 아닙니다. 균일하게 한정하면 신호가 없어집니다(평균 오류율에는 맞아도 개별 사례 수준에서는 무의미). 필요한 것은 각 답마다 모델의 실제 내부 상태를 반영하는 한정 — 즉 faithful uncertainty입니다.
2. 배경 — 신뢰성을 어떻게 측정하는가
2.1 문제 범위
저자들은 두 배포 모드를 구분합니다.
- Parametric LLM: 자기 파라미터에만 의존.
- Tool-Augmented LLM: 검색엔진·API 등 외부 소스를 추론 시점에 활용.
이 논문은 주로 전자를 다루며(도구 사용은 §5에서), extrinsic hallucination(실세계 지식과 어긋나는 생성)을 표적으로 삼습니다. intrinsic hallucination(주어진 원문과 모순)이나 추론 오류는 범위 밖입니다.
또한 흔한 오해나 head knowledge 위주의 평가는 환각의 심각성을 가릴 수 있으므로, “롱테일(long tail)” 지식 — 매우 희귀한 엔티티에 대한 단순·명시적 사실(예: “캐나다 리얼리티 시리즈 To Serve and Protect는 미국 어느 TV 방송국에서 데뷔했는가?”) — 을 묻는 벤치마크에 집중합니다.
2.2 유용성-사실성 트레이드오프
모델은 확신 없는 질문에 모두 답을 거부하면 환각 0% 를 손쉽게 달성하지만, 그러면 쓸모없어집니다. 따라서 견고한 평가는 두 가지를 함께 봐야 합니다.
- Accuracy: 전체 정답률.
- Attempted accuracy: 답을 시도한 부분집합에서의 정답률.
이상적 행동은 둘 다 최대화하는 것이며, F1이나 Omniscience Index 같은 요약 지표를 씁니다.
2.3 Calibration vs Discrimination — 이 논문의 심장
| 개념 | 정의 | 한계 |
|---|---|---|
| Calibration | 신뢰도 점수와 경험적 정답률의 정렬. 신뢰도 $p$를 부여한 예측 중 정확히 $p$%가 맞으면 완벽히 보정됨 | 집계적 속성 — 개별 답의 진위는 못 가림 |
| Discrimination | 신뢰도로 맞은 답과 틀린 답을 구분하는 능력 | 환각을 실제로 없애려면 이것이 필요 |
결정적 사례: 모든 답에 0.6을 부여하고 실제로 60%를 맞히는 신호는 완벽히 calibrated이지만 discrimination이 0입니다. 즉, calibration은 discrimination을 함의하지 않습니다.
인지과학의 메타인지 문헌에서도 유사한 구분이 있는데, 여기서는 resolution이라는 개념이 calibration보다 메타인지 정확도를 더 잘 진단한다고 봅니다 (Fleming & Lau, 2014).
2.4 기존 완화 전략
- 학습 시점(training-time): 데이터 필터링·정규화, 비사실 출력 패널티, 협력 게임 기반 보상, linguistic calibration을 통한 과신 완화.
- 추론 시점(inference-time): 커스텀 디코딩, 내부 신호 활용, self-verification.
3. 환각은 왜 지속되는가
3.1 이론적 천장(Theoretical Ceiling)
환각이 자기회귀 텍스트 생성의 구조적 필연이라는 선행 연구들이 있습니다.
- Banerjee et al. (2025), Xu et al. (2024): 정지 문제(Halting Problem)·대각화 논증으로, 어떤 계산 가능한 모델도 진실을 보편적으로 검증하거나 모든 정답 함수를 학습할 수 없음을 증명.
- Kalai & Vempala (2024): 다른 사실로부터 진위를 추론할 수 없는 사실을 생성할 때, calibrated 모델은 수학적으로 환각할 수밖에 없음.
- Kalavasis et al. (2025): consistency와 breadth 사이의 형식적 트레이드오프 — 환각률을 임계치 아래로 낮추면 출력 다양성이 급감(mode-collapse) 함.
3.2 Discrimination Gap
선행 연구는 LLM에서 잘 보정된 신뢰도를 뽑을 수 있다는 긍정적 결과에 집중했지만, 평균 오류율을 아는 것(calibration) 과 어떤 사례가 오류인지 아는 것(discrimination) 은 전혀 다릅니다. 표준 완화 기법의 실패는 바로 이 discriminative power의 근본적 부족에서 비롯된다는 것이 저자들의 추측입니다.

Figure 2. 왼쪽(Calibration). 기저 오류율 25%인 모델을 시뮬레이션. 곡선이 대각선에 밀착해 강한 보정(smECE ≈ 0.014) 을 보이지만, 히스토그램을 보면 맞은 답과 틀린 답이 비슷한 신뢰도를 공유한다. 오른쪽(Discrimination). Utility-Error 트레이드오프 곡선. 보정이 좋아도 환각률을 25% → 5%로 낮추려면 유효한 답의 52%를 폐기해야 한다(10% 목표여도 28% 손실). 이것이 utility tax를 시각화한 것이다.
문헌의 AUROC로 본 discrimination gap (AUROC=1.0 완벽, 0.5 무작위):
| 출처 | 설정 | AUROC |
|---|---|---|
| Farquhar et al. (2024) | 30개 model×task 평균 (semantic entropy) | 0.79 |
| Savage et al. (2025) | GPT-4, 의료 QA 최고치 | 0.79 |
| Kang et al. (2025) | GPT-4o-mini, 인물 전기 생성 (롱테일과 유사) | 0.68–0.72 |
| 일반적 범위 | 현실적 factual QA | 0.70–0.85 |
이 범위로는 utility tax를 벗어날 수 없습니다. Figure 2의 시뮬레이션은 AUROC=0.71(문헌 평균과 일치)이며, 이때 오류율 25%→5%는 유효 답변 52% 폐기를 요구합니다. 0.85 천장에서도 세금은 ~28%, AUROC ≥ 0.95가 되어야 비로소 utility tax가 5% 미만으로 무시할 만해지는데, 이는 지식 집약 과제에서 보고된 어떤 기법보다도 한참 높습니다.
3.3 정황 증거(Corroborating Anomalies)
- Truthfulness probe의 빈약한 일반화 + confident hallucination → 맞은/틀린 답을 구분할 정보가 모델의 잠재 상태(latent state)에조차 부재한 경우가 많음.
- 고급 감독의 실패: 모델이 의도적 안전 위반은 “자백”하도록 정렬되지만 이 능력이 환각에는 전이되지 않음 → 환각은 단순 행동 버그가 아니라 discrimination gap에서 기인. 모델은 내부적으로 표현조차 못 하는 오류를 보고하도록 정렬될 수 없습니다.
- 유용성 최적화가 환각을 악화: “thinking”이 환각률을 높이고 abstention을 떨어뜨림 → 확장된 chain-of-thought와 끈기를 보상하는 학습이 틀린 답을 합리화하게 만듦.
3.4 경험적 트레이드오프
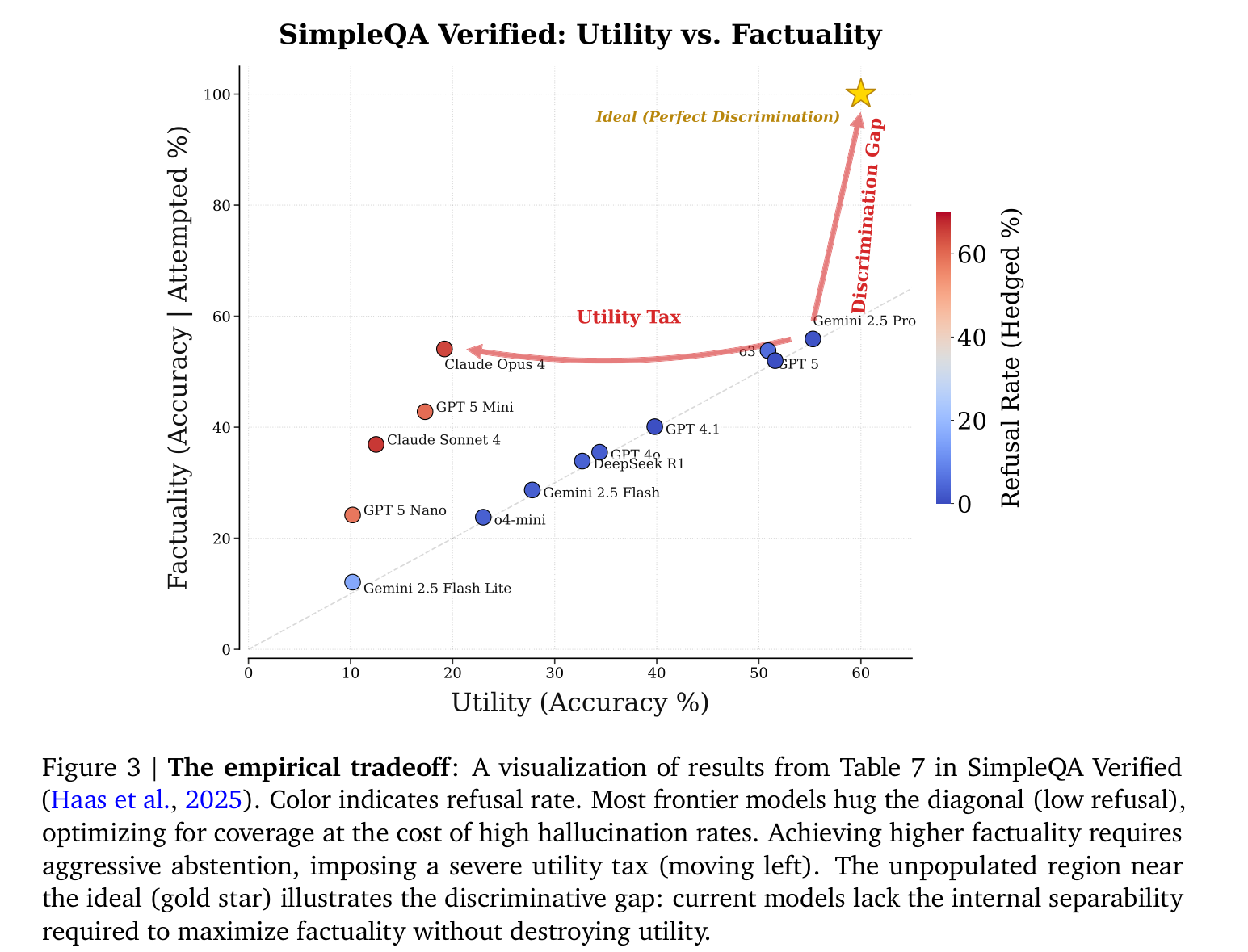
Figure 3. SimpleQA Verified(Haas et al., 2025) Table 7의 시각화. 색은 기권율(refusal rate). 대부분의 프런티어 모델은 대각선에 밀착(낮은 기권)해 커버리지를 위해 높은 환각률을 감수한다. 사실성을 높이려는 모델(붉은 계열)은 위가 아니라 왼쪽으로 이동 — 유효 답을 버리며 utility tax를 낸다. 이상적 영역인 우상단(금색 별)은 완전히 비어 있고, 이 빈 공간이 곧 모델이 현재 도달하지 못하는 discrimination gap이다.
4. Faithful Uncertainty
§3의 난점을 고려해, 저자들은 연구 목표를 현실적으로 조정하자고 제안합니다 — 지식 확장은 여지가 있는 곳에서 계속하되, 남은 불확실성을 충실히 표현하는 목표로 보완하자는 것입니다.
4.1 목표 정의
Yona et al. (2024)의 틀을 차용해, faithful uncertainty = 모델의 내부 상태와 언어화된 출력의 정렬로 정의합니다.
- Intrinsic uncertainty(내부 불확실성): 자기 주장의 의미에 대한 통계적 확신. 높은 불확실성 = 다시 물으면 모순되는 답을 낼 확률이 높음.
- Linguistic uncertainty(언어적 불확실성): 생성된 응답에서 말로 표현한 확신 (예: “90% 확신합니다”, “틀릴 수도 있습니다”).
모델이 언어적 불확실성이 내부 불확실성을 정확히 반영하면, 그 모델은 불확실성을 충실히(faithfully) 표현한다고 한다. 환각의 완전 제거는 출력이 외부 세계와 일치해야 하지만, faithful uncertainty는 출력이 내부 상태와 일치하면 된다.
4.2 실현 가능성 논거(Feasibility)
유한한 파라미터를 무한한 세계에 매핑하는 것은 이론적으로 한계가 있지만, 내부 파라미터를 출력 문자열에 매핑하는 것은 완전히 관측 가능한 closed-loop 문제입니다. 활성 공간에 보편적인 “truth direction”이 없더라도, 신뢰도 신호 자체는 모델 가중치로부터 계산 가능합니다.
모델은 $P(\text{answer}) = 0.6$이 실세계에서 “진실”에 해당하는지 알 필요가 없습니다. 내부 확신이 0.6이라는 것을 감지하고 그것을 적절한 언어적 한정에 매핑하기만 하면 됩니다. faithfulness의 정답(ground truth)이 시스템 내부에 있기 때문에, 아키텍처·데이터·학습 레시피 개선으로 이론적으로 풀 수 있습니다.
4.3 Reliable Utility(신뢰할 수 있는 유용성)
내부 확신이 60%인 답들의 집합을 생각해 봅시다. 잘 보정돼 있다면 정확히 60%가 맞습니다.
- 환각 완전 제거 목표: 40%의 환각을 피하려면 집합 전체를 기권 → 맞는 60%까지 버려 유용성 손실.
- Faithful uncertainty 패러다임: 답을 생성하되 적절한 인식적 표지(epistemic marker)로 감쌈. 여기서 confident error는 여전히 환각(단, 충실한 환각)이지만, 적절한 불확실성으로 감싼 오류는 유용한 가설로 전환됩니다.
저자들은 이를 reliable utility라 부릅니다 — 신뢰를 해치지 않으면서 제공 정보량을 최대화. 이는 인간 전문가의 신뢰 형성 방식을 닮았습니다. 우리가 의사를 신뢰하는 것은 전지(omniscient)해서가 아니라, 확신하는 진단과 단지 검증 중인 가설을 충실히 구분해 전달하기 때문입니다.
4.4 연구 기회 — 다룰 만한 여지(Tractable Headroom)
현재 SOTA 모델은 이 목표에서 멀리 떨어져 있습니다 — 내부 불확실성이 낮을 때조차 높은 언어적 확신을 표현하는 경향이 있습니다. 다만 메타인지 프롬프팅, 지도 미세조정(SFT), 내부 표현 기반 steering 등에서 유망한 초기 결과가 나오고 있어, 지식 확장과 함께 가면 더 박식하면서 동시에 더 신뢰할 수 있는 모델로 가는 길이 됩니다.
5. 에이전트 시대의 Metacognition
도구를 쓰는 agentic AI는 “아무 사실이나 검색하면 되니 불확실성 인식이 필요 없지 않냐”고 생각하기 쉽습니다. 저자들은 정반대라고 주장합니다 — 도구는 faithful uncertainty의 필요를 없애기는커녕 증폭시킵니다. 자기 불확실성을 모르면 모델은 (1) 언제 도구를 호출할지 정할 수 없고(비효율적 남용 또는 위험한 미사용), (2) 충돌이 생길 때 검색 결과와 자기 믿음을 적절히 저울질할 수 없습니다.
- 도구는 신뢰성 문제를 가린다(Mask): 최종 출력 정확도만 보는 벤치마크는 검색 품질을 보상할 뿐, 모델이 왜 검색해야 하는지 이해했는지는 시험하지 않습니다. 도구가 실패하거나 예상 밖 결과를 주면 이 취약성이 드러납니다.
- Storage vs Control: 도구는 storage 문제(모든 사실을 인코딩할 필요 없음)는 풀지만, control 문제(검색·검증·오케스트레이션의 통제)를 만듭니다. 에이전트는 내부 지식으로 충분한 때와 하네스에 위임할 때를 판단해야 하며, 이 결정은 곧 불확실성으로 정의됩니다.
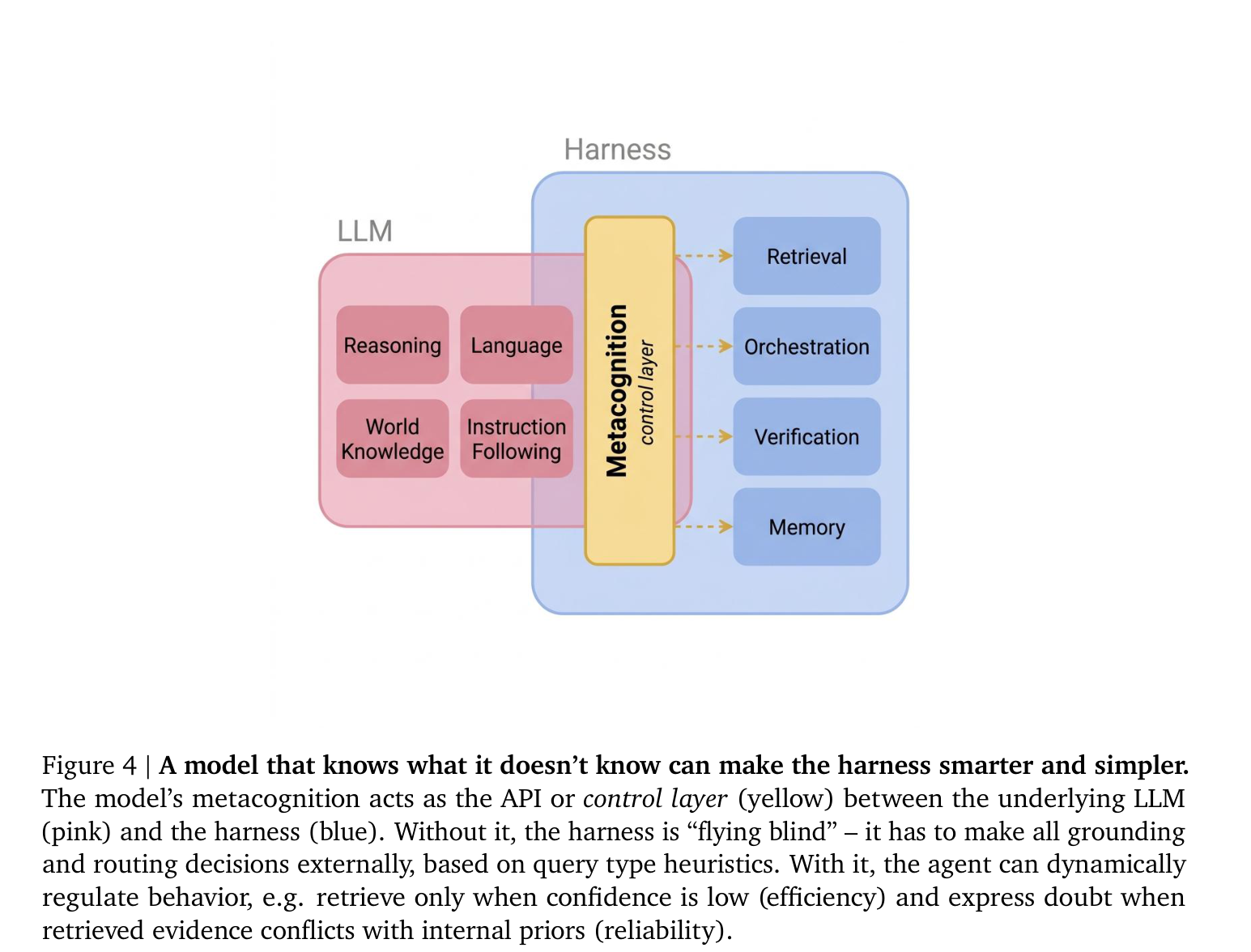
Figure 4. 모델의 메타인지는 기저 LLM(분홍)과 하네스(파랑) 사이의 API / control layer(노랑) 로 작동한다. 이것이 없으면 하네스는 “눈을 가린 채 비행” — 질의 유형 휴리스틱에 의존해 모든 grounding·routing 결정을 외부에서 내려야 한다. 있으면 에이전트는 동적으로 행동을 조절 — 확신이 낮을 때만 검색하고(효율), 검색 증거가 내부 사전 믿음과 충돌하면 의심을 표현(신뢰성)할 수 있다.
- 메타인지적 LLM을 향하여: 인간 메타인지에서 두 과정을 강조 — introspection(자기 불확실성 평가) 과 regulation(그 평가에 따른 행동 조정). 정적 휴리스틱이나 과도하게 설계된 하네스에 의존하는 현재 에이전트와 달리, 개방형 환경의 미래 에이전트는 정보가 충분한 때·검증할 때·멈출 때를 판단하는 동적 제어가 필요합니다. 메타인지는 환각 제거의 보완재일 뿐 아니라 신뢰할 수 있는 자율 에이전트의 전제 조건입니다.
6. 연구 커뮤니티에 대한 제언 (Call to Action)
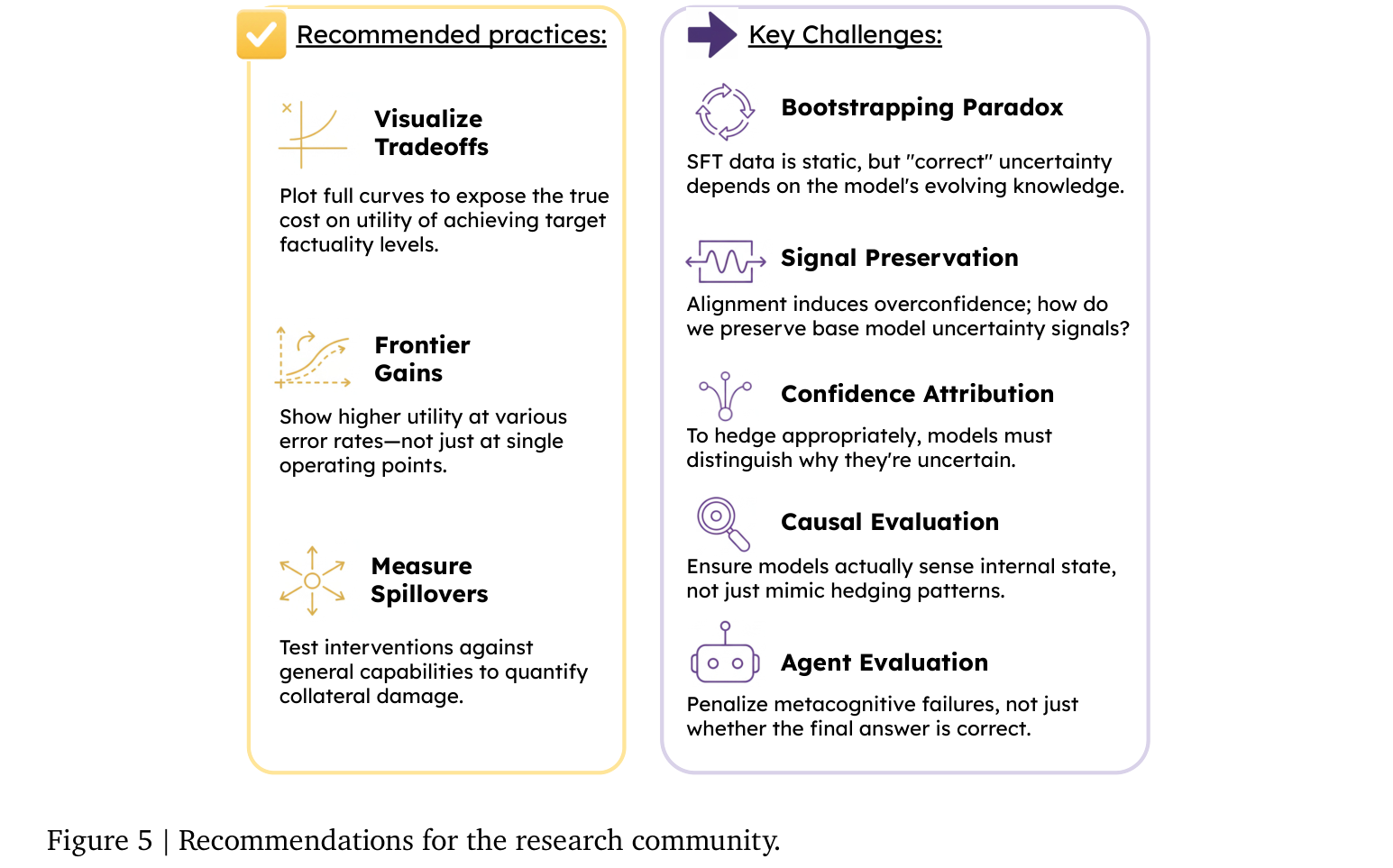
Figure 5. 메타인지적 LLM을 위한 핵심 과제(오른쪽)와 환각 완화 평가를 위한 권장 실천(왼쪽).
6.1 메타인지적 LLM을 위한 핵심 과제
| 과제 | 내용 |
|---|---|
| Bootstrapping Paradox | 베이스 모델은 권위적 인터넷 텍스트로 학습돼 자연스레 의심을 표현하지 않음. 한정의 문법을 가르치려면 SFT가 필요한데, SFT 데이터는 정적인 반면 “올바른” 불확실성 라벨은 모델의 현재 지식 상태에 따라 동적. 모델이 아는 사실에 “모른다” 라벨을 학습시키면 환각된 불확실성/확신을 유발 |
| Signal Preservation | 사전학습 모델은 잘 보정된 불확실성 표현을 갖지만 post-training에서 열화됨. 표준 정렬은 mode-seeking을 유발해 aligned 모델을 베이스보다 과신하게 만듦 → 안전·지시따르기 정렬을 하면서도 불확실성 신호를 보존하는 “uncertainty-preserving alignment” 필요 |
| Confidence Attribution | 스칼라 신뢰도 하나로는 부족. 모델은 서로 다른 이유로 불확실 — aleatoric(프롬프트 모호성), epistemic(지식 부족), normative(정렬 행동 모호성). 불확실성의 원천을 추적해 적절한 한정 표현에 매핑(“당신이 X를 무슨 뜻으로 썼는지에 달려 있다” vs “X가 기억나지 않는다”) |
| Causal Evaluation | 모델이 내부 상태를 실제로 감지하는지, 아니면 단지 한정 패턴을 흉내내는지(예: “희귀 엔티티가 있으면 무조건 한정”) 구분해야 함. concept injection, cross-model 평가, 전략적 게임 등 |
| Agent Evaluation | end-to-end 정답이 아니라 과정 기반 제어로 평가 이동. 아는 사실을 검색하는 비효율, 알려진 지식과 충돌하는 소스를 신뢰하는 sycophancy 같은 메타인지 실패를 패널티 |
6.2 더 나은 환각 완화 평가
- Utility-Error 트레이드오프를 시각화하라: ECE(분포 전체 평균이라 gap을 가림)나 AUROC(특정 작동점 비용을 가림) 같은 요약 지표 대신, 목표 오류율을 위해 얼마나 유용성을 희생하는지 드러내는 전체 Utility-Error 곡선(Figure 2 오른쪽)을 제시하라.
- 프런티어 개선을 입증하라: “환각을 줄였다”는 주장은 대개 기존 곡선 위를 미끄러진 것(기권 임계치 상향)에 불과. 단일 작동점(“95% 정확도 달성”)이 아니라 고정된 오류율에서 더 높은 유용성을 보여야 함.
- 전체적 부작용(spillover)을 측정하라: 롱테일 거부로 튜닝하면 head 지식에 회피적이 되거나 추론·코딩·창작 능력이 떨어질 수 있음. 타깃 집합의 recall 손실만이 아니라 일반 능력 전반의 helpfulness 저하로 비용을 정량화하라.
7. 반론과 재반박 (Alternative Viewpoints)
| 반론 | 저자들의 재반박 |
|---|---|
| 7.1 사실성을 deprioritize 해선 안 된다 — 메타인지에 자원을 쏟으면 사실성 진전이 느려지지 않나? | faithful uncertainty는 지식 확장의 대체재가 아니라 보완재. 멀티모달 등 신생 영역엔 기본 사실성 여지가 많고, 두 목표는 시너지 — 박식하면서 메타인지 좋은 모델이 둘 중 하나만 가진 모델보다 엄밀히 우월 |
| 7.2 사용자는 확신을 선호한다 — 끊임없는 한정은 마찰을 일으키고 무능해 보임 | 이 논문의 범위(§2)를 무시한 반론. faithful uncertainty는 환각이 오히려 바람직한 창작 영역을 표적으로 하지 않음. 장문 생성에서도 특정 코드 줄·날짜를 국소적으로(localized) 표시하면 사용자를 막지 않고 가치를 더함 |
| 7.3 잠재적 진실은 존재하니 더 좋은 probe만 있으면 된다 — §3의 난점은 과장 | latent truth 탐색은 가치 있지만, 롱테일 전체에 보편적 truth 표현이 존재한다는 강한 가정이 필요(저자들은 회의적). 반면 faithful uncertainty는 오늘 당장의 구체적 여지 — 모델이 이미 접근 가능한 신뢰도 신호를 가졌다는 견고한 증거가 있음. 또한 reasoning 모델은 환각을 더 하면서도 확신은 더 잘 표현 → 메타인지 신호가 사실성 신호와 구별됨을 시사 |
8. 결론 — 정직(Honesty)으로서의 불확실성
환각의 완전 제거는 discrimination gap 때문에 근본적 난관에 부딪히며, 저자들은 faithful uncertainty를 보완 목표로 제안합니다. 이 메타인지적 자각은 LLM이 agentic 시스템으로 진화할수록 견고한 도구 사용의 control layer로서 더욱 중요해집니다.
faithful uncertainty는 본질적으로 honesty의 한 형태 — 모델이 거짓 확신을 투사하지 않고 자기 인식적 상태를 정확히 표현하도록 요구하는 것입니다. 이는 사용자가 검증하고, 다른 출처를 찾고, 스스로 판단을 내릴 수 있게 하여 적절한 인간 감독(human oversight) 을 가능케 합니다. 이 비전의 실현에는 두 가지 전환이 필요합니다 — 모델 개발(현재 벤치마크가 사실 정확도에만 집중)과 사용자 기대(불확실성 표현을 기대하고 적절히 해석할 수 있는 사용자).
부록 — 핵심 지표와 수식 (Appendix B)
Yona et al. (2024)에 기반해 faithful uncertainty를 조작적으로 정의하는 핵심 개념입니다.
① Intrinsic uncertainty (내부 불확실성). 질의 $Q$와 후보 주장 $A$에 대해, 모델 $M$이 반복 샘플링으로 생성한 답 $A_1, \dots, A_k$가 $A$와 모순되지 않을수록 내부 확신이 높습니다.
\[\mathrm{conf}_M(A) \equiv 1 - \frac{1}{k}\sum_{i=1}^{k} \mathbf{1}[A_i \text{ contradicts } A]\]② Linguistic uncertainty (언어적 불확실성 = decisiveness). 응답 $R$ 속 주장 $A$가 얼마나 단호하게 전달됐는지를, 독자가 $R$의 언어만 보고 $A$가 참이라 부여할 확률로 측정합니다 (LLM-as-a-judge로 구현).
\[\mathrm{dec}(A; R, Q) = \Pr[A \text{ is True} \mid R, Q]\]③ Faithfulness. 응답의 decisiveness가 주장별로 내부 확신을 따라갈수록 충실합니다.
\[\mathrm{faithfulness}_M(R; Q) \equiv 1 - \frac{1}{|\mathcal{A}(R)|}\sum_{A \in \mathcal{A}(R)} \big|\, \mathrm{dec}(A; R, Q) - \mathrm{conf}_M(A) \,\big|\]값이 1이면 완벽한 정렬, 낮을수록 체계적 과대/과소 한정을 뜻합니다.
④ cMFG (conditional Mean Faithful Generation). 원시 faithfulness는 모델의 확신 분포에 교란되므로, 신뢰도 구간(bin)별로 균등 평균한 지표입니다.
cMFG = 0.5 는 decisiveness가 실제 확신과 무관한 전략에 해당합니다. 현재 SOTA 모델은 대체로 0.5–0.7 에 머물러, 표현된 불확실성이 내부 확신과 약하게만 정렬됨을 보여줍니다.
부록 A — Figure 2 시뮬레이션. 합성 데이터 $N=25{,}000$, 기저 환각률 25%. 정답 신뢰도는 $\mathrm{Beta}(1.8, 1.0)$(고확신 편향), 오답은 $\mathrm{Beta}(1.0, 1.3)$(저확신 편향)에서 샘플링. Isotonic Regression으로 거의 완벽한 보정(smECE ≈ 0.014)을 강제해, 관찰된 트레이드오프가 오보정이 아니라 분포의 겹침에서만 비롯되도록 격리. 기각 임계치 $\tau \in [0,1]$를 훑어 Utility-Error 곡선을 산출.
한 줄 정리
“모델이 언제 틀리는지 완벽히 알 수는 없어도, 언제 불확실한지는 알 수 있다.” — 환각을 confident error로 재정의하고, 내부 확신과 언어적 확신을 정렬하는 faithful uncertainty를 통해 신뢰성과 유용성의 교착을 풀자는 제안. 그리고 이 메타인지는 에이전트 시대에 도구 사용을 다스리는 control layer가 된다.
References
- Yona, Geva, Matias. Hallucinations Undermine Trust; Metacognition is a Way Forward. arXiv:2605.01428 (2026). — 본 논문
- Yona et al. Can Large Language Models Faithfully Express Their Intrinsic Uncertainty in Words? (2024) — faithful uncertainty·cMFG 정의의 원천
- Haas, Yona, D’Antonio, Goldshtein, Das. SimpleQA Verified. arXiv:2509.07968 (2025) — Figure 3 데이터
- Nakkiran et al. (2025) — Figure 2 reliability diagram의 기반
- Farquhar, Kossen, Kuhn, Gal. Detecting hallucinations using semantic entropy. Nature (2024) — AUROC 평균 0.79
- Kang et al. (2025); Savage et al. (2025) — factual QA AUROC 측정
- Banerjee et al. (2025); Xu et al. (2024); Kalai & Vempala (2024); Kalavasis et al. (2025) — 이론적 천장
- Kadavath et al. (2022); Tian et al. (2023b); Lin et al. (2022) — LLM calibration
- Fleming & Lau (2014) — 인지과학의 metacognition·resolution