TurboQuant: 정보 이론적 최적에 근접하는 온라인 벡터 양자화
논문: TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
블로그: Google Research Blog
저자: Amir Zandieh, Majid Daliri, Majid Hadian, Vahab Mirrokni (Google Research, NYU, Google DeepMind)
발표일: 2025년 4월 28일
핵심 요약
TurboQuant는 Google Research에서 제안한 데이터 비의존적(data-oblivious) 벡터 양자화 알고리즘으로, Shannon의 정보 이론적 하한에 근접하는 거의 최적의 왜곡률(near-optimal distortion rate) 을 달성합니다.
| 구분 | 기존 방법 (PQ, KIVI 등) | TurboQuant |
|---|---|---|
| 전처리 | 데이터 의존적 codebook 학습 필요 | 전처리 불필요 (온라인 즉시 적용) |
| 이론적 보장 | 없거나 부족 | 정보 이론적 하한의 2.7배 이내 |
| KV cache 3.5-bit | 성능 하락 발생 | Full Cache(16-bit)와 동일 성능 |
| 인덱싱 시간 | 수십~수천 초 | 사실상 0초 (0.001초 수준) |
| 내적 추정 | 편향(biased) 가능 | 비편향(unbiased) 보장 |
1. 서론 — 왜 벡터 양자화가 중요한가
벡터 양자화(VQ)는 고차원 벡터의 부동소수점 좌표를 저비트 정수로 변환하면서 기하학적 구조(내적, 거리)를 최대한 보존하는 기술입니다.
핵심 응용 분야 3가지
1. LLM 추론 가속
- LLM의 가중치·활성화를 양자화하면 HBM↔SRAM 통신 병목을 완화하여 추론 비용을 절감
- 내적 연산의 정확도 보존이 핵심
2. KV Cache 압축
- Transformer 디코더는 이전 토큰의 Key/Value 임베딩을 KV cache에 저장
- 모델 크기 × 레이어 수 × 어텐션 헤드 수 × 컨텍스트 길이에 비례하여 메모리 소비 증가
- 긴 컨텍스트 모델에서 메모리/속도의 주요 병목
- KV cache의 유클리드 구조(내적, 거리) 보존이 모델 성능 유지에 필수
3. 최근접 이웃 검색 (Nearest Neighbor Search)
- 벡터 데이터베이스(Pinecone, Qdrant, Elastic Search 등)의 핵심 기술
- RAG(Retrieval-Augmented Generation) 및 정보 검색의 기반
- 데이터베이스 벡터를 압축하면서 내적 검색 정확도를 유지해야 함
기존 방법의 한계
기존 VQ 알고리즘은 두 가지 문제 중 하나를 겪습니다:
- 가속기 비호환: 벡터화(vectorization) 불가능하여 GPU/TPU에서 느림 → KV cache 같은 실시간 응용에 부적합
- 비최적 왜곡: 비트 폭 대비 왜곡 경계(distortion bound)가 이론적 최적에 훨씬 못 미침
TurboQuant는 이 두 가지를 동시에 해결합니다.
2. 문제 정의
목표
$d$차원 벡터를 $b$-bit 폭으로 양자화하는 맵 $Q$와 복원 맵 $Q^{-1}$을 설계합니다.
최소화할 왜곡 측정 2가지
MSE (Mean Squared Error) 왜곡:
\[D_{mse} = \mathbb{E}\left[\|x - Q^{-1}(Q(x))\|^2\right]\]원본 벡터와 복원 벡터 간 유클리드 거리의 기대값입니다.
내적(Inner Product) 왜곡:
\[D_{prod} = \mathbb{E}\left[(\langle y, x \rangle - \langle y, Q^{-1}(Q(x)) \rangle)^2\right]\]원본 내적과 복원 내적 간 오차의 기대값이며, 추가로 비편향성(unbiasedness)을 요구합니다:
\[\mathbb{E}[\langle y, Q^{-1}(Q(x)) \rangle] = \langle y, x \rangle\]설계 원칙
- 최악의 경우(worst-case) 입력에 대해 보장 제공 (데이터 분포 가정 없음)
- 무작위화된(randomized) 양자화기 → 기대값 기준의 왜곡 정의
- 두 가지 핵심 프리미티브: Quant (양자화)와 DeQuant (복원)
3. 관련 연구
| 분류 | 방법 | 특징 | 한계 |
|---|---|---|---|
| 온라인 (Data-oblivious) | KIVI, QJL, PolarQuant | 전처리 불필요, 즉시 적용 | 왜곡 경계가 최적에 못 미침 |
| 오프라인 (Data-dependent) | GPTQ, AWQ, SmoothQuant, QuIP | Hessian 등 2차 정보로 튜닝 | 무거운 전처리, 동적 데이터에 부적합 |
| 토큰 프루닝 | SnapKV, PyramidKV, H2O | 덜 중요한 토큰 제거 | 정보 손실 위험, 이론적 보장 없음 |
| Product Quantization | PQ, OPQ, RabitQ | codebook 기반 NN 검색 | 인덱싱에 k-means 필요 (느림) |
TurboQuant의 위치: 온라인 방법이면서도 오프라인 방법과 동등하거나 더 나은 성능을 달성하고, 정보 이론적 최적에 근접하는 이론적 보장까지 제공합니다.
4. 예비 지식 (Preliminaries)
4.1 초구(Hypersphere) 위의 좌표 분포
Lemma 1: $d$차원 단위 초구 위에 균일 분포된 점의 각 좌표는 Beta 분포를 따릅니다.
\[x_j \sim f_X(x) = \frac{\Gamma(d/2)}{\sqrt{\pi} \cdot \Gamma((d-1)/2)} (1 - x^2)^{(d-3)/2}\]- 고차원에서 이 분포는 정규분포 $\mathcal{N}(0, 1/d)$로 수렴
- 서로 다른 좌표들은 거의 독립 → 좌표별 독립 양자화의 이론적 근거
이것이 TurboQuant의 핵심 관찰입니다: 랜덤 회전 후 각 좌표를 독립적으로 양자화해도 거의 최적의 왜곡을 달성할 수 있다는 것입니다.
4.2 Shannon 하한 (Shannon Lower Bound, SLB)
Shannon의 손실 소스 코딩 정리에서 유도된 어떤 압축 알고리즘이든 달성할 수 없는 왜곡의 하한입니다.
Lemma 3 (단위 초구에 대한 SLB): 비트 복잡도 $B$에 대해
\[D(B) \geq 2^{-2B/d}\]이 하한이 TurboQuant의 최적성을 증명하는 기준선 역할을 합니다.
4.3 QJL (Quantized Johnson-Lindenstrauss)
1-bit 내적 양자화기로, TurboQuant의 두 번째 단계에서 사용됩니다.
- 정의: $Q_{qjl}(x) = \text{sign}(S \cdot x)$, 여기서 $S$는 i.i.d. $\mathcal{N}(0,1)$ 항목을 가진 랜덤 행렬
- 복원: $Q^{-1}_{qjl}(z) = \frac{\sqrt{\pi/2}}{d} \cdot S^\top \cdot z$
- 보장: 비편향 내적 추정 + 분산 경계 $\frac{\pi}{2d} \cdot |y|^2$
5. TurboQuant 알고리즘
TurboQuant는 목적에 따라 두 가지 변형을 제공합니다.
5.1 TurboQuant_mse — MSE 최적화
목표: 원본과 복원 벡터 간의 MSE를 최소화
알고리즘 (Algorithm 1):
| 단계 | 설명 |
|---|---|
| 셋업 | (1) 랜덤 회전 행렬 $\Pi$ 생성 (QR 분해), (2) 최적 codebook 사전 계산 |
| 양자화 Quant(x) | $y = \Pi \cdot x$ (랜덤 회전) → 각 좌표에서 가장 가까운 centroid의 인덱스 저장 |
| 복원 DeQuant(idx) | 인덱스로 centroid 복원 → $\Pi^\top$ 곱하여 원래 기저로 회전 복귀 |
핵심 아이디어 — 왜 랜덤 회전인가?
- 입력 무관화: 어떤 벡터든 회전 후에는 초구 위의 균일 분포가 됨 → worst-case 제거
- 좌표 독립화: 고차원에서 회전된 벡터의 각 좌표는 거의 독립인 Beta 분포를 따름
- 최적 스칼라 양자화 적용 가능: 좌표 간 상관관계를 무시하고 각 좌표에 독립적으로 최적 1D 양자화(Lloyd-Max) 적용
최적 스칼라 양자화 문제:
\[C(f_X, b) = \min \sum_{i=1}^{2^b} \int_{(c_{i-1}+c_i)/2}^{(c_i+c_{i+1})/2} |x - c_i|^2 \cdot f_X(x) \, dx\]- 구간 $[-1, 1]$을 $2^b$개 클러스터로 분할하는 연속 1차원 k-means 문제
- Voronoi 분할(centroid 중간점이 경계)로 최적 해를 구함
- 실용적인 비트 폭(b=1,2,3,4)에 대해 한 번만 풀고 저장 → 이후 즉시 사용
Theorem 1 — 성능 보장:
\[D_{mse} \leq \frac{3\sqrt{\pi}}{2} \cdot \frac{1}{4^b}\]| 비트 폭 (b) | MSE 왜곡 ($D_{mse}$) |
|---|---|
| b = 1 | ≈ 0.36 |
| b = 2 | ≈ 0.117 |
| b = 3 | ≈ 0.03 |
| b = 4 | ≈ 0.009 |
5.2 TurboQuant_prod — 내적 최적화
문제: MSE 최적 양자화는 내적 추정에 편향(bias)이 있다
$b=1$일 때 TurboQuant_mse의 내적 추정은 $2/\pi \approx 0.637$의 곱셈 편향을 가집니다. 비트 폭이 증가하면 편향이 줄어들지만 완전히 사라지지는 않습니다.
해결책: 2단계 알고리즘 (Algorithm 2)
| 단계 | 설명 |
|---|---|
| 1단계 | TurboQuant_mse를 $(b-1)$ 비트로 적용 → 잔차 $r = x - \tilde{x}_{mse}$ 계산 |
| 2단계 | 잔차에 QJL(1-bit) 적용: $qjl = \text{sign}(S \cdot r)$, $\gamma = |r|_2$ 저장 |
| 복원 | $\tilde{x} = \tilde{x}_{mse} + \frac{\sqrt{\pi/2}}{d} \cdot \gamma \cdot S^\top \cdot qjl$ |
왜 이것이 작동하는가?
- 1단계에서 MSE를 최소화하여 잔차 $r$의 L2 norm을 최대한 줄임
- 2단계에서 QJL이 잔차의 내적을 비편향으로 추정
- 전체적으로: $(b-1)$비트 MSE 양자화 + 1비트 QJL = $b$비트 비편향 내적 양자화
Theorem 2 — 성능 보장:
- 비편향성: $\mathbb{E}[\langle y, \tilde{x} \rangle] = \langle y, x \rangle$
| 비트 폭 (b) | 내적 왜곡 ($D_{prod}$) |
|---|---|
| b = 1 | ≈ 1.57 / d |
| b = 2 | ≈ 0.56 / d |
| b = 3 | ≈ 0.18 / d |
| b = 4 | ≈ 0.047 / d |
5.3 하한 (Lower Bounds) — TurboQuant의 최적성 증명
Theorem 3: Shannon 하한 + Yao의 미니맥스 원리를 활용하여 어떤 양자화 알고리즘이든 달성할 수 없는 하한을 증명합니다.
| 왜곡 종류 | 하한 | TurboQuant 상한 | 격차 |
|---|---|---|---|
| MSE | $1 / 4^b$ | $(3\sqrt{\pi}/2) / 4^b$ | ≈ 2.7배 |
| 내적 | $|y|^2 / (d \cdot 4^b)$ | $(3\sqrt{\pi}/2)^2 \cdot |y|^2 / (d \cdot 4^b)$ | ≈ 7.4배 |
- 비트 폭이 낮을수록 격차가 줄어듦 ($b=1$에서 MSE 격차는 약 1.45배)
- 핵심 의미: TurboQuant는 정보 이론적으로 가능한 최선에 상수 배 이내로 근접
6. 실험 결과
모든 실험은 NVIDIA A100 GPU 1대에서 수행되었습니다.
6.1 이론적 검증 (Empirical Validation)
데이터셋: DBpedia Entities (OpenAI 임베딩, d=1536), 100K 데이터 + 1K 쿼리
Figure 1: 내적 오차 분포
(a) TurboQuant_prod — 모든 비트 폭에서 0 중심 대칭 (비편향)
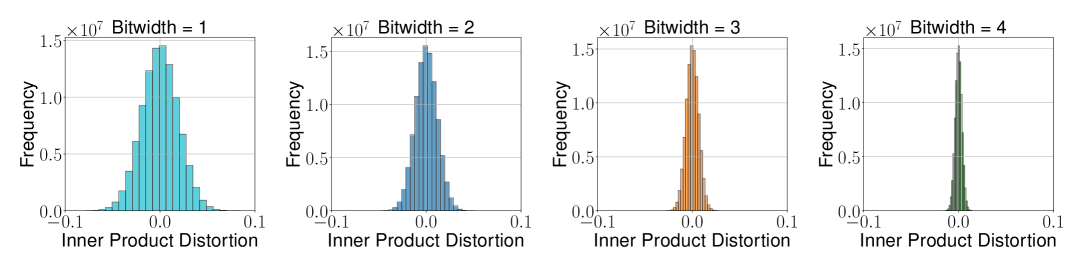
(b) TurboQuant_mse — 양의 방향으로 편향 존재 (비트 폭 증가 시 감소)
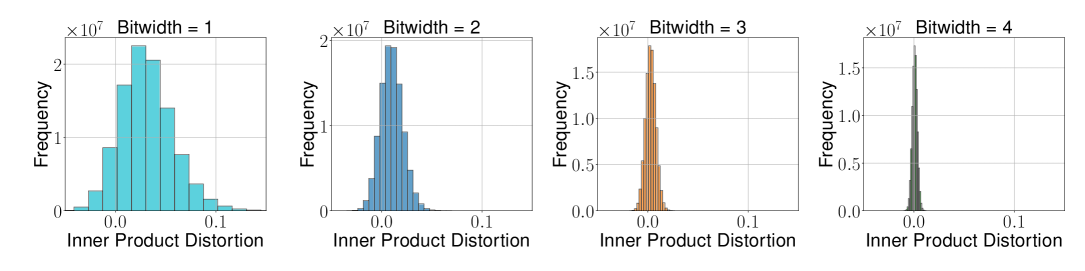
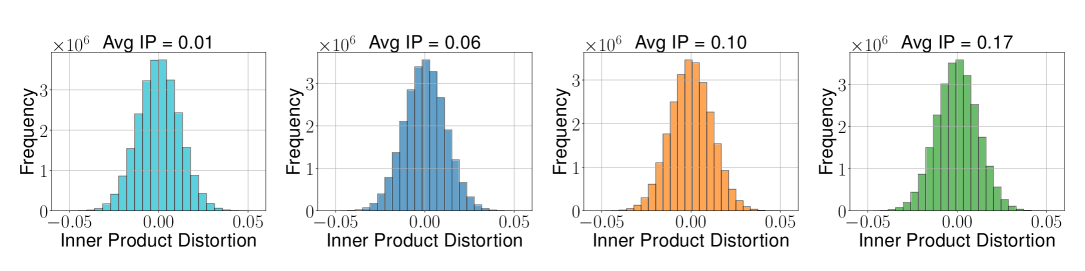
Figure 2: 평균 내적에 따른 분산 변화 (bit-width = 2)
(a) TurboQuant_prod — 분산이 평균 내적에 무관하게 일정
(b) TurboQuant_mse — 평균 내적이 클수록 편향이 증가
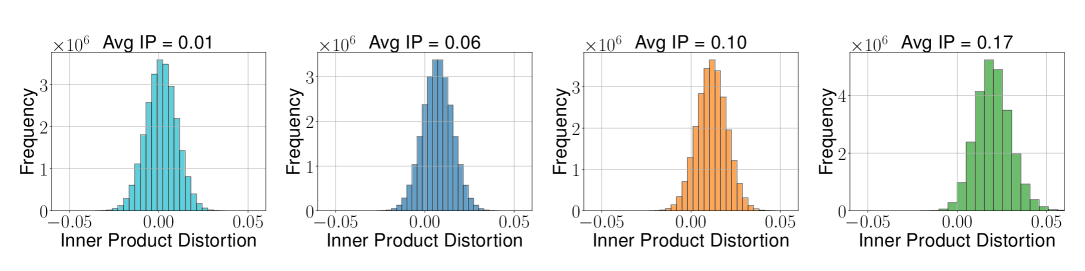
Figure 3: 이론적 경계 vs 실측값
(a) Inner Product Error — 실측값이 이론적 상한·하한 사이에 정확히 위치
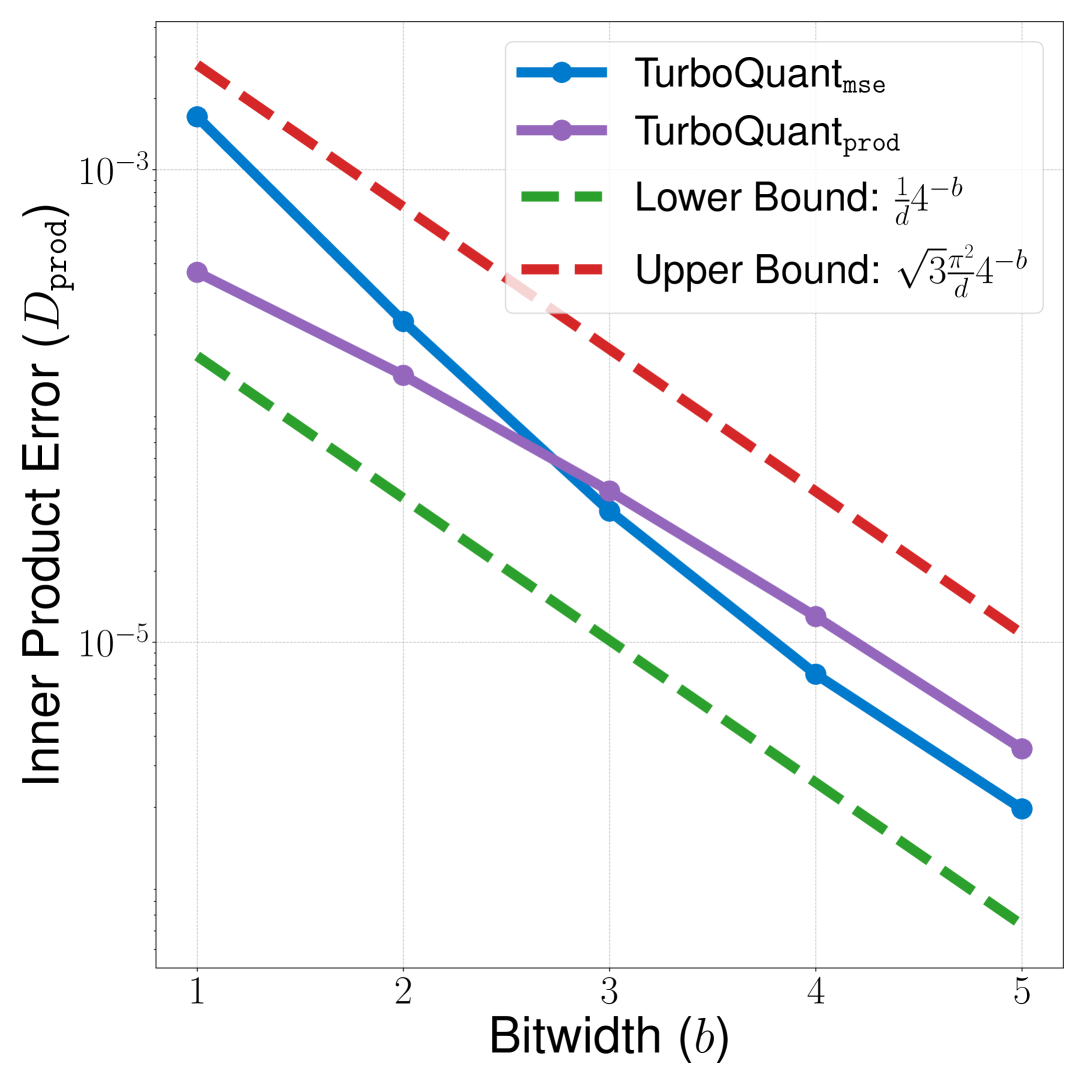
(b) MSE — MSE도 이론적 경계와 일치
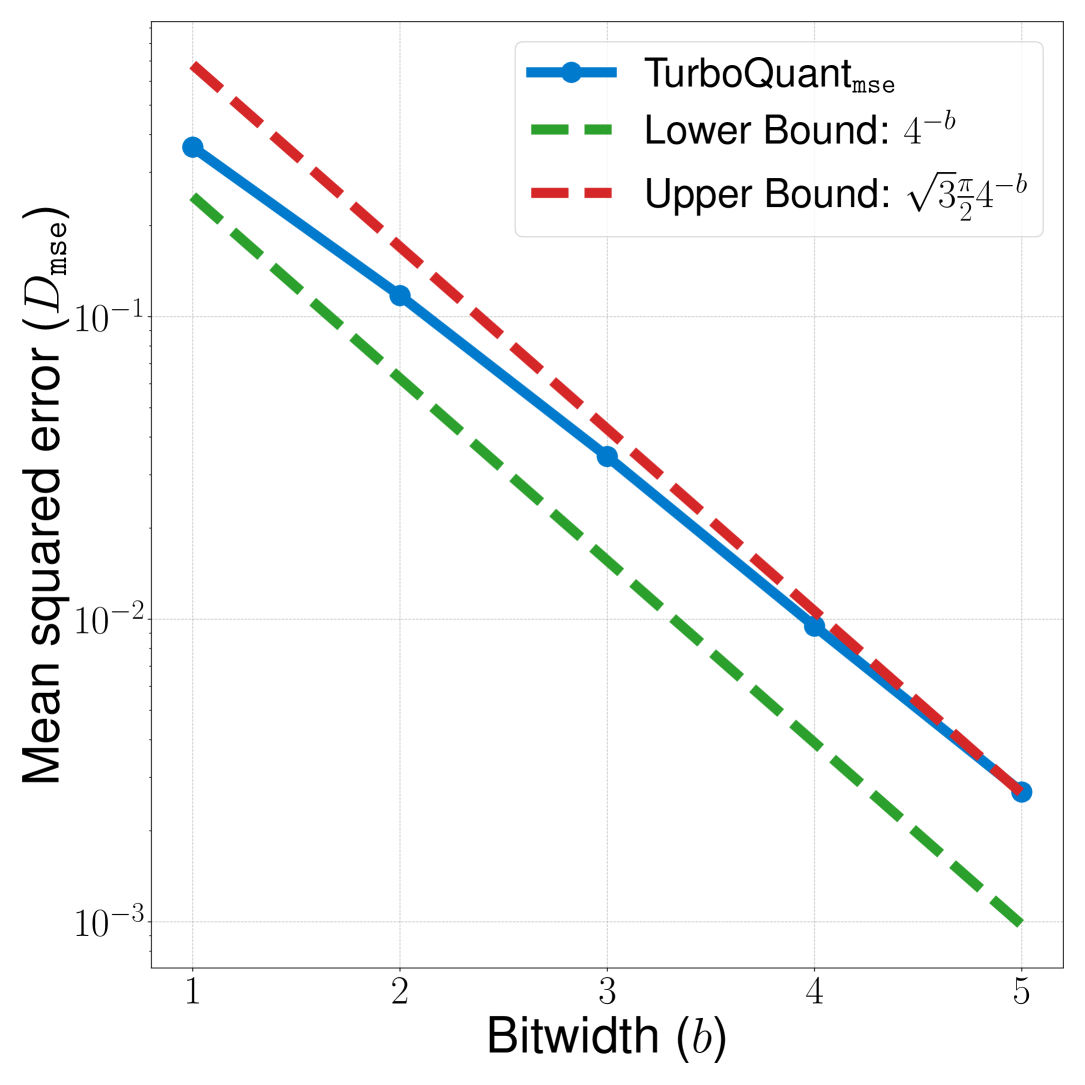
핵심 발견:
- TurboQuant_prod는 모든 비트 폭에서 비편향 내적 추정 확인
- TurboQuant_mse는 내적에 편향 존재하지만 비트 폭 증가 시 수렴
- 관측된 왜곡이 이론적 상한·하한과 정확히 일치
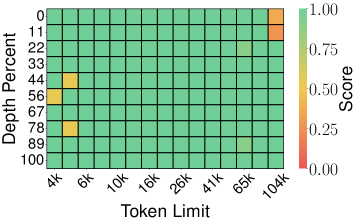
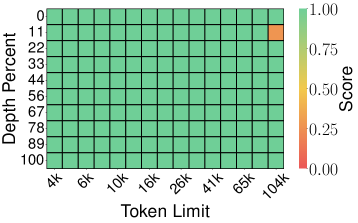
6.2 Needle-in-a-Haystack 테스트
설정: Llama-3.1-8B-Instruct, 4K~104K 토큰 문서, 메모리 압축률 0.25 (KV cache의 25%만 사용)
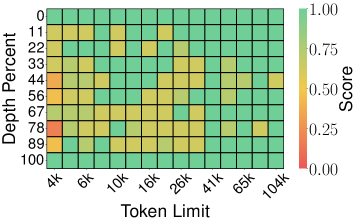
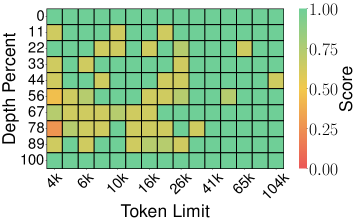
Figure 4: Needle-in-a-Haystack 결과
토큰 프루닝 방법:
| SnapKV (Score: 0.858) | PyramidKV (Score: 0.895) |
|---|---|
 |  |
양자화 방법:
| KIVI (Score: 0.981) | PolarQuant (Score: 0.995) |
|---|---|
 |  |
기준선 vs TurboQuant:
| Full-Precision (Score: 0.997) | TurboQuant (Score: 0.997) |
|---|---|
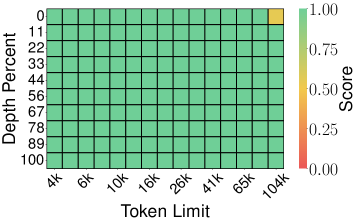 | 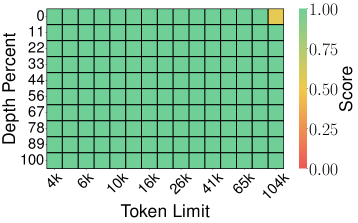 |
핵심 발견: 이론적 보장이 있는 양자화 방법(TurboQuant, PolarQuant)이 토큰 프루닝(SnapKV, PyramidKV)이나 이론적 보장 없는 스칼라 양자화(KIVI)보다 우수합니다. TurboQuant는 4× 압축에서도 Full-Precision과 동일한 0.997 score를 달성합니다.
6.3 LongBench 종합 평가
설정: LongBench-E, Llama-3.1-8B-Instruct + Ministral-7B-Instruct
차별점: TurboQuant는 기존 방법과 달리 생성 중 스트리밍 토큰에도 양자화를 적용합니다.
비정수 비트 폭의 구현 방법:
- 채널을 outlier / non-outlier로 분리하여 두 개의 TurboQuant 인스턴스 적용
- 예시: 2.5-bit = 32개 outlier 채널(3-bit) + 96개 일반 채널(2-bit) → $(32 \times 3 + 96 \times 2)/128 = 2.5$
결과 (Llama-3.1-8B-Instruct):
| 방법 | KV bit | SingleQA | MultiQA | Summary | Few-shot | Synthetic | Code | 평균 |
|---|---|---|---|---|---|---|---|---|
| Full Cache | 16 | 45.29 | 45.16 | 26.55 | 68.38 | 59.54 | 46.28 | 50.06 |
| KIVI | 3 | 43.38 | 37.99 | 27.16 | 68.38 | 59.50 | 44.68 | 48.50 |
| KIVI | 5 | 45.04 | 45.70 | 26.47 | 68.57 | 59.55 | 46.41 | 50.16 |
| PolarQuant | 3.9 | 45.18 | 44.48 | 26.23 | 68.25 | 60.07 | 45.24 | 49.78 |
| TurboQuant | 2.5 | 44.16 | 44.96 | 24.80 | 68.01 | 59.65 | 45.76 | 49.44 |
| TurboQuant | 3.5 | 45.01 | 45.31 | 26.00 | 68.63 | 59.95 | 46.17 | 50.06 |
핵심 발견:
- TurboQuant 3.5-bit = Full Cache 16-bit과 동일한 50.06점 → 4.5× 이상 압축에도 성능 무손실
- TurboQuant 2.5-bit(49.44)가 KIVI 3-bit(48.50)보다 더 적은 비트로 더 높은 성능
- Ministral-7B에서도 2.5-bit로 49.62/49.89 달성 (미미한 하락)
6.4 최근접 이웃 검색 (Nearest Neighbor Search)
데이터셋: DBpedia (d=1536, d=3072) + GloVe (d=200)
양자화 시간 비교 (4-bit):
| 방법 | d=200 | d=1536 | d=3072 |
|---|---|---|---|
| Product Quantization | 37.04초 | 239.75초 | 494.42초 |
| RabitQ | 597.25초 | 2267.59초 | 3957.19초 |
| TurboQuant | 0.0007초 | 0.0013초 | 0.0021초 |
TurboQuant의 인덱싱 시간은 PQ 대비 수만 배, RabitQ 대비 수백만 배 빠릅니다.
Figure 5: Recall@1@k 비교
(a) GloVe (d=200) — 저차원에서 TurboQuant 2-bit가 PQ 4-bit와 유사한 recall
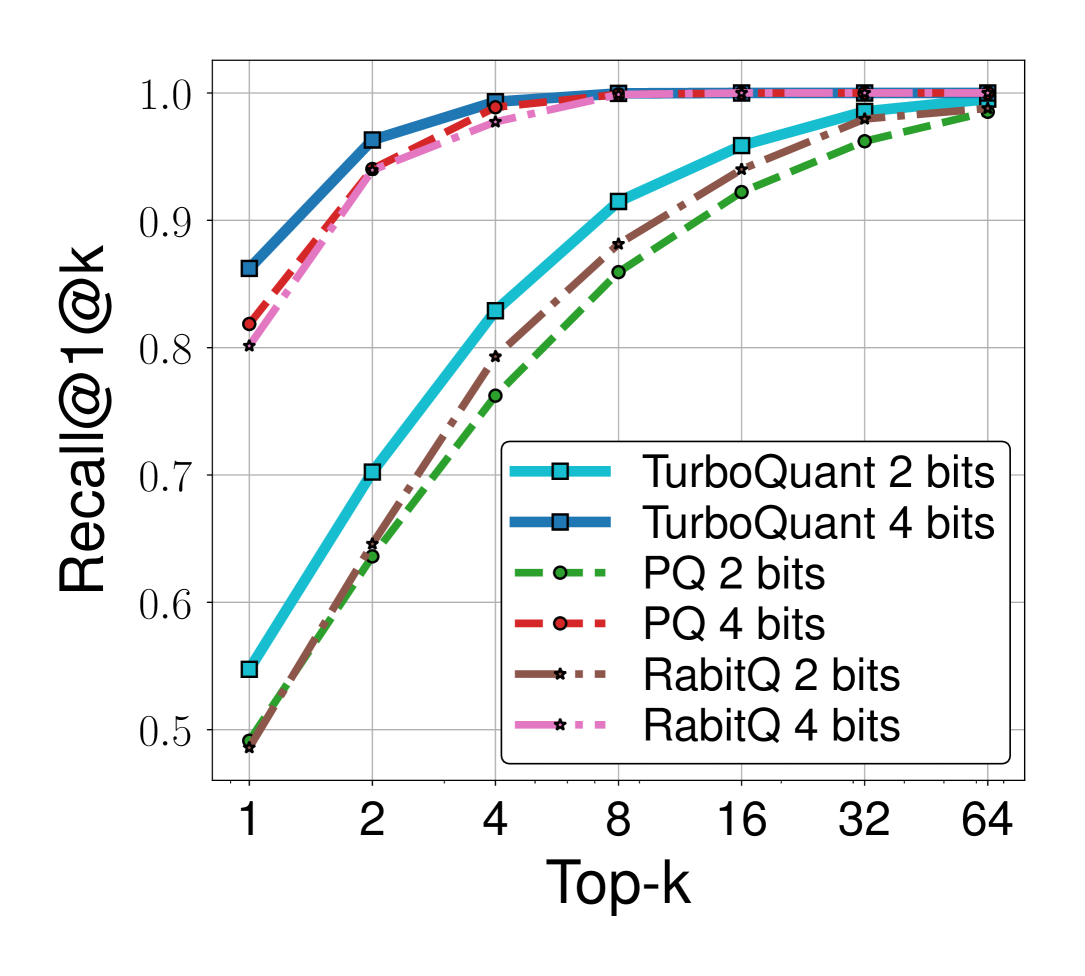
(b) OpenAI3 (d=1536)
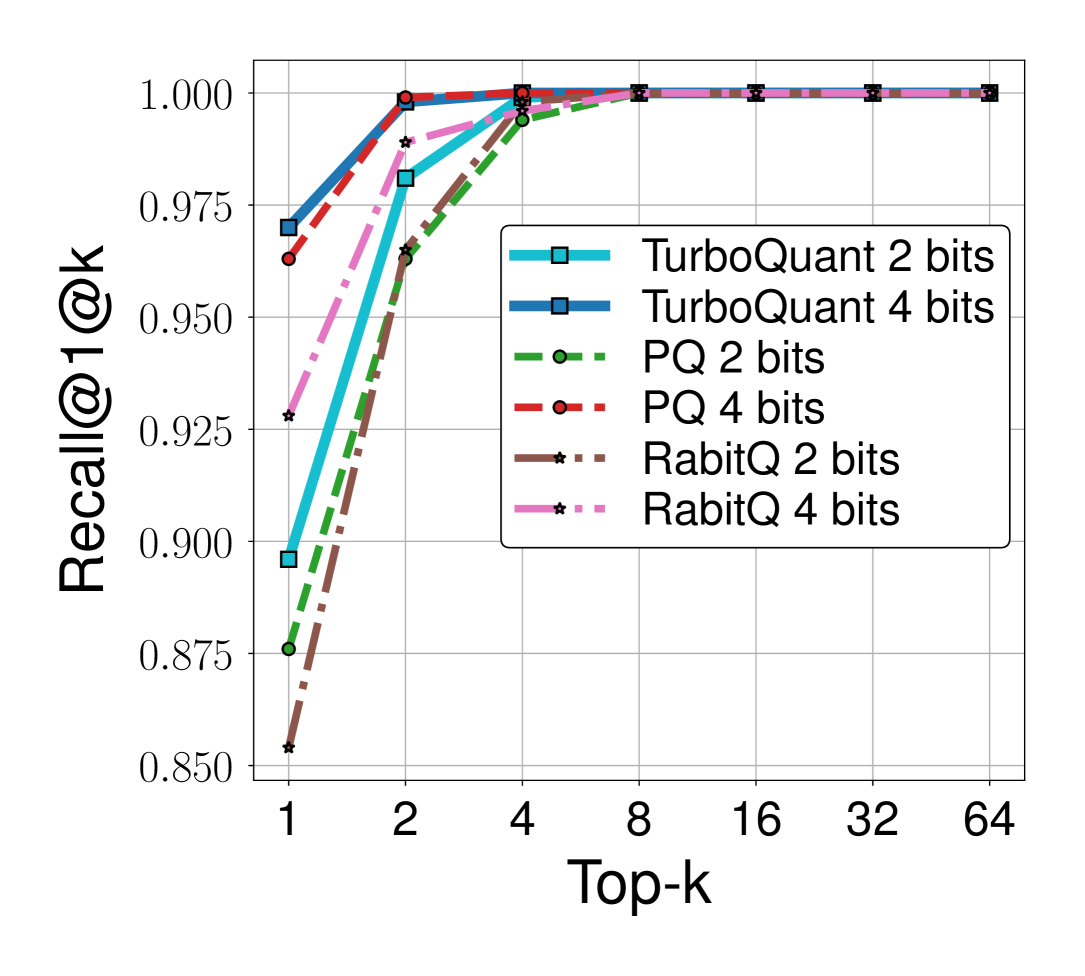
(c) OpenAI3 (d=3072)
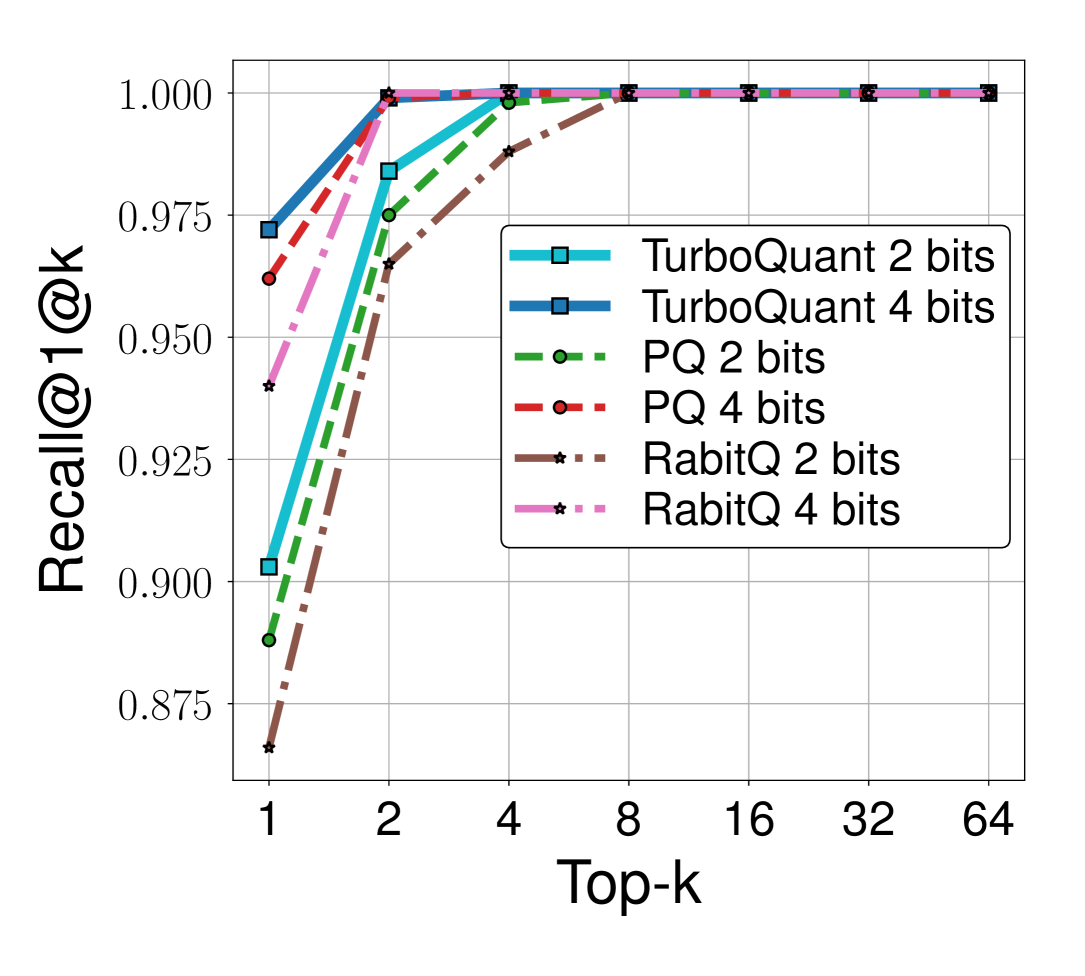
핵심 발견:
- 모든 데이터셋과 비트 폭에서 TurboQuant가 PQ와 RabitQ를 일관되게 능가
- 특히 저차원(d=200)에서 차이가 가장 두드러짐
- PQ는 학습/평가 데이터셋이 동일하여 유리한 조건임에도 TurboQuant에 열세
7. 핵심 기술 요약
전체 파이프라인
1
2
3
4
5
6
7
8
9
10
11
12
13
입력 벡터 x
│
├── [TurboQuant_mse] ─────────────────────────────────┐
│ ① 랜덤 회전: y = Π·x │
│ ② 좌표별 최적 스칼라 양자화: idx = nearest centroid │
│ ③ 복원: x̃ = Π^T · codebook[idx] │
│ │
├── [TurboQuant_prod] ────────────────────────────────┤
│ ① TurboQuant_mse를 (b-1)비트로 적용 │
│ ② 잔차 계산: r = x - x̃_mse │
│ ③ QJL 적용: qjl = sign(S·r), γ = ||r|| │
│ ④ 복원: x̃ = x̃_mse + √(π/2)·γ·S^T·qjl/d │
└──────────────────────────────────────────────────────┘
왜 codebook이 필요 없는가?
기존 PQ는 데이터에서 k-means로 codebook을 학습해야 합니다. TurboQuant는:
- 랜덤 회전으로 입력을 정규화 → 데이터 분포에 무관
- Beta 분포의 수학적 성질을 활용 → 최적 centroid를 해석적으로 사전 계산
- 미리 계산된 centroid는 차원 $d$와 비트 폭 $b$에만 의존 → 데이터 비의존적
비정수 비트 폭 (Outlier 처리)
실제 KV cache에는 특정 채널에 큰 값(outlier)이 집중됩니다. TurboQuant는:
- 채널을 outlier와 non-outlier로 분리
- 두 개의 독립적인 TurboQuant 인스턴스를 적용하여 outlier에 더 높은 비트 할당
- 이로써 2.5, 3.5 등 비정수 비트 폭을 자연스럽게 구현
8. 의의 및 한계
의의
- 이론적 엄밀성: 정보 이론적 하한에 상수 배 이내로 근접하는 것을 증명 — 이 분야에서 드문 성과
- 실용적 우수성: KV cache 양자화에서 3.5-bit로 무손실 압축, 2.5-bit로 최소 손실 달성
- 극단적 효율성: 인덱싱 시간이 사실상 0 — 실시간/온라인 응용에 이상적
- 두 가지 목적 동시 달성: MSE 최적화와 비편향 내적 추정을 하나의 프레임워크로 해결
- 가속기 친화적: 행렬 곱셈과 element-wise 연산만으로 구성 → GPU/TPU에서 완전 벡터화 가능
한계 및 고려사항
- 실험이 JAX/TPU 환경 기준 — PyTorch/GPU에서의 성능은 커스텀 CUDA 커널 최적화에 의존
- 랜덤 회전 행렬 $\Pi$의 저장·적용에 $O(d^2)$ 비용 발생 (큰 차원에서 오버헤드)
- 현재 공식 구현은 JAX 기반만 제공