270개 API를 가진 구조해석 SW를 LLM에 연결하기 - GEN NX MCP 서버 만들기
MIDASIT의 구조해석 소프트웨어 GEN NX를 MCP(Model Context Protocol) 서버로 감싸서 LLM의 도구로 노출하는 방법을 다룹니다.
- 빠른 시작 — 설치, 설정, MCP 클라이언트 등록, 사용 예시
- 전체 구조 — 5개 sub-server, 동적 tool 생성 파이프라인
- MCP 클라이언트-서버 간 실제 동작 —
list_tools와instructions핸드셰이크, 매 턴마다 재전송되는 tool 리스트, 반응형 에이전트 루프 - 구현 원리 — 65개 JSON 스키마에서 159개 tool이 만들어지는 과정, 두 가지 tool 등록 방식, toolset 필터링
프로젝트: github.com/Gabriel-Hong/mcp-gennx · FastMCP 3.x, Python 3.11+
1. 배경
GEN NX는 MIDASIT에서 개발한 범용 구조해석 소프트웨어입니다. 건물, 교량, 플랜트 등의 구조물을 3D로 모델링하고, 하중(load)을 적용해 응력(stress)·변위(displacement)를 해석합니다. 모든 작업이 GUI 기반이라 “3경간 연속보를 만들고, 자중과 활하중을 적용한 뒤 고유치해석을 돌려줘” 같은 자연어 요청을 곧장 처리할 수 없습니다.
하지만 GEN NX는 270여 개의 REST API를 제공합니다. 이 API를 LLM이 호출할 수 있게 만들면 자연어 → 구조모델 → 해석까지의 흐름이 성립합니다.
| Function Calling | MCP | |
|---|---|---|
| 재사용성 | 각 LLM API에 맞춰 tool 정의를 따로 관리 | 한 번 만들면 Claude Desktop, Claude Code, Cursor 등 어디서든 사용 |
| 메타데이터 | 이름, 설명, JSON Schema | + ToolAnnotations (readOnly, destructive, idempotent) |
| 가시성 제어 | 직접 구현 필요 | 태그·환경 변수로 tool 노출 범위 제어 가능 |
MCP는 Anthropic이 2024년 말 공개한 개방형 프로토콜로, 클라이언트와 서버를 완전히 분리합니다. GEN NX처럼 API 수가 많고 도메인이 뚜렷한 대상에 적합합니다.
GEN NX의 전체 API는 270여 개이며, 이 서버는 현재 46개 엔드포인트(최대 159개 tool)를 커버합니다. 나머지(해석 결과 조회, 설계 검토 등)는 향후 확장 예정입니다.
2. 빠른 시작
동작 원리를 설명하기 전에, 먼저 설치하고 연결하는 과정부터 살펴봅니다.
2.1 설치 및 설정
1
2
3
git clone https://github.com/Gabriel-Hong/mcp-gennx.git
cd mcp-gennx
pip install -e .
.env.example을 .env로 복사하고 환경 변수를 설정합니다.
| 변수 | 기본값 | 설명 |
|---|---|---|
GENNX_API_BASE_URL | http://localhost:8080 | GEN NX REST API 주소 (예: https://moa-engineers.midasit.com:443/gen) |
GENNX_MAPI_KEY | (빈 값) | MIDAS 사용자 포털에서 발급받은 MAPI 키. MAPI-Key 헤더로 전송됩니다. 로컬 인스턴스 사용 시 생략 가능 |
GENNX_API_TIMEOUT | 30.0 | API 요청 타임아웃 (초) |
TOOLSETS | default | 노출할 toolset (5.5절 참고) |
READ_ONLY | false | true면 GET tool만 노출 |
LOG_LEVEL | INFO | 로깅 레벨 |
2.2 MCP 클라이언트에 등록
Claude Code:
1
2
3
4
claude mcp add gennx \
-e GENNX_API_BASE_URL=https://moa-engineers.midasit.com:443/gen \
-e GENNX_MAPI_KEY=your-mapi-key-here \
-- mcp-gennx
Claude Desktop / Cursor / Windsurf (JSON config):
1
2
3
4
5
6
7
8
9
10
11
{
"mcpServers": {
"gennx": {
"command": "mcp-gennx",
"env": {
"GENNX_API_BASE_URL": "https://moa-engineers.midasit.com:443/gen",
"GENNX_MAPI_KEY": "your-mapi-key-here"
}
}
}
}
2.3 사용 예시
등록 후 자연어로 요청하면 MCP 서버를 통해 GEN NX가 제어됩니다. 아래는 실제로 Claude Code에서 재료(material)를 복사하는 과정입니다.
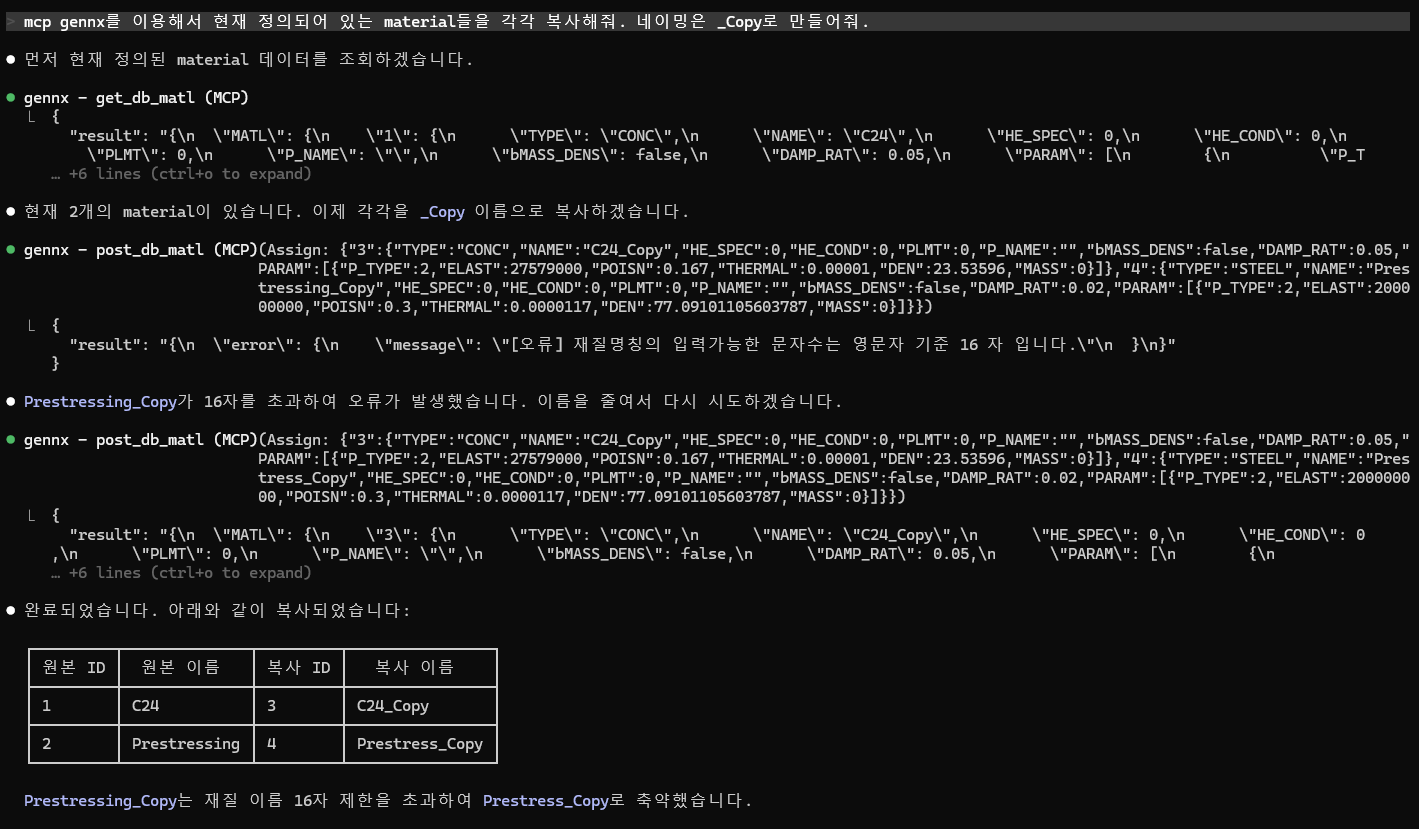 Claude Code가
Claude Code가 get_db_matl로 기존 재료를 조회한 뒤, post_db_matl로 복사본을 생성하는 모습
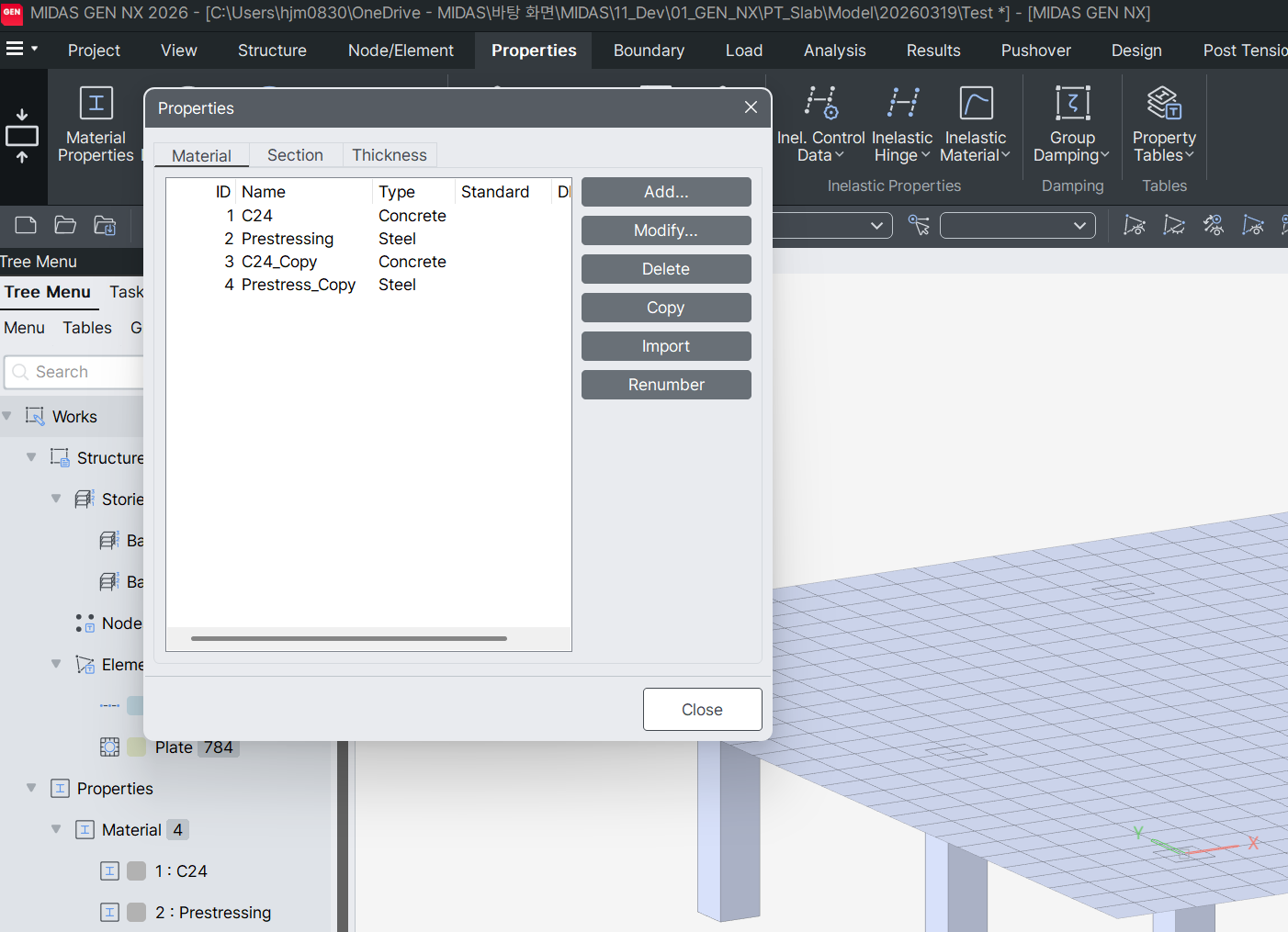 GEN NX의 Material Properties 창에서 복사된 재료(C24_Copy, Prestress_Copy)가 실제로 추가된 것을 확인
GEN NX의 Material Properties 창에서 복사된 재료(C24_Copy, Prestress_Copy)가 실제로 추가된 것을 확인
다른 예시로, 구조 모델을 처음부터 만드는 흐름은 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
사용자: 3경간 연속보를 만들어줘. 경간 길이는 5m씩.
AI: [post_db_node 호출]
Assign: {"1":{"X":0,"Y":0,"Z":0}, "2":{"X":5,"Y":0,"Z":0},
"3":{"X":10,"Y":0,"Z":0}, "4":{"X":15,"Y":0,"Z":0}}
→ 4개 절점 생성 완료
[post_db_matl 호출]
Assign: {"1":{"TYPE":"STEEL","STANDARD":"KS-SteelDesign(2025)","DB":"SS275"}}
→ 재료 생성 완료
[post_db_sect, post_db_elem 호출] ← 한 턴에 병렬 호출
→ 단면 정의 + 3개 보 요소 생성 완료
사용자: 양 끝을 핀 지점으로 잡고, 자중 적용해서 고유치해석 돌려줘.
AI: [post_db_cons 호출] → 절점 1, 4에 핀 지점 적용
[post_db_stld 호출] → 하중 케이스 "자중" 생성
[post_db_bodf 호출] → 자중(body force) 적용
[post_db_eigv 호출] → 고유치해석 파라미터 설정
[post_doc_anal 호출] → 해석 실행
해석이 완료되었습니다. 1차 고유진동수는 ...
이 흐름이 내부적으로 어떻게 동작하는지를 이어서 설명합니다.
3. 전체 구조
3.1 5개 sub-server
구조공학의 도메인 경계를 따라 5개의 sub-server로 분할했습니다.
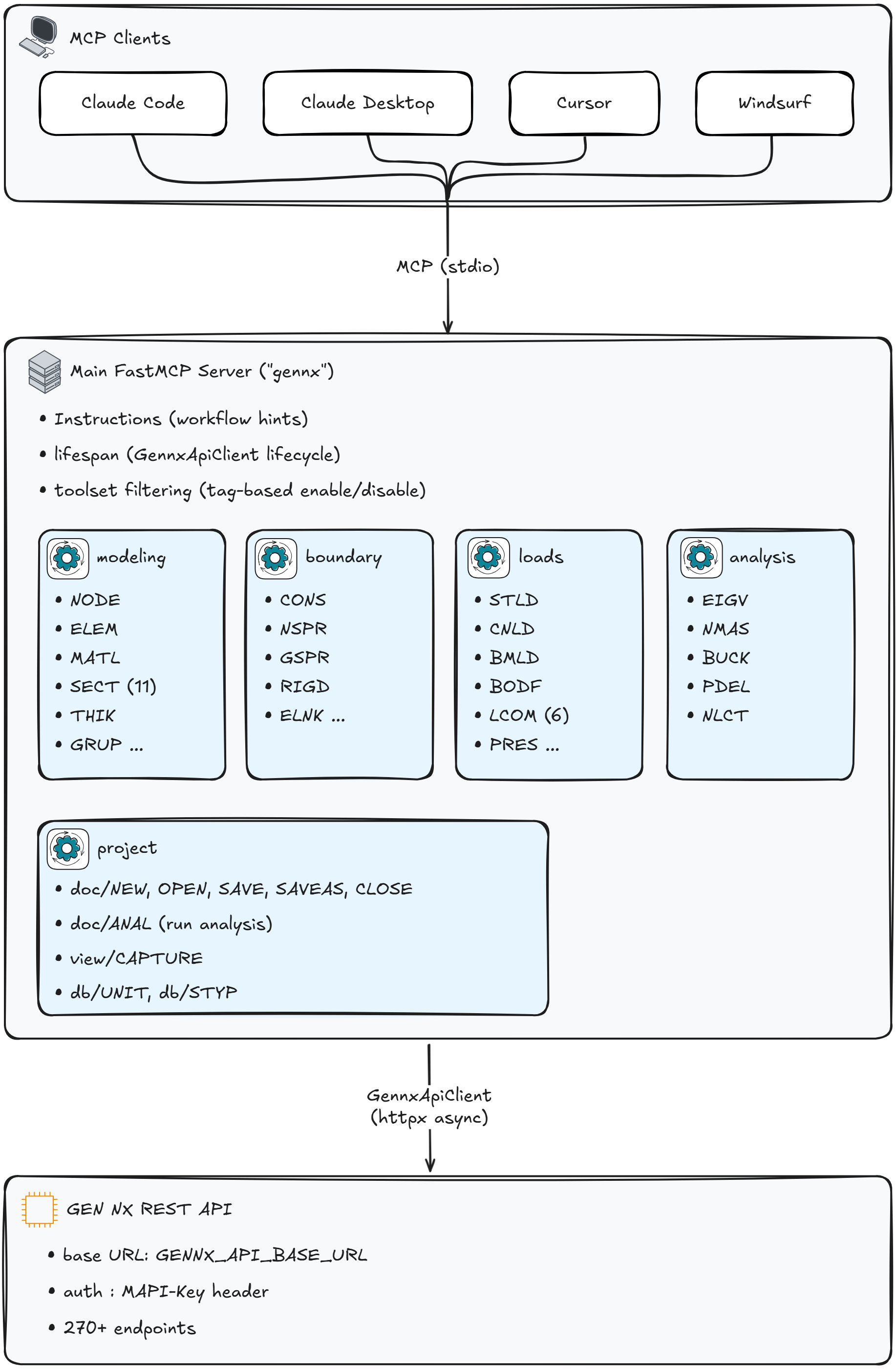
각 sub-server는 독립된 FastMCP 인스턴스이고, main.mount()로 메인 서버에 결합됩니다.
3.2 서버 조립
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
# src/mcp_gennx/server.py
def create_server() -> FastMCP:
settings = GennxSettings()
# 1. 메인 서버 + lifespan
main = FastMCP("gennx", instructions=INSTRUCTIONS, lifespan=app_lifespan)
# 2. 스키마 로드
schema_dir = Path(__file__).parent / "schemas" / "raw"
registry = SchemaRegistry(schema_dir)
factory = ToolFactory()
# 3. 5개 sub-server 마운트
main.mount(create_modeling_server(registry, factory))
main.mount(create_boundary_server(registry, factory))
main.mount(create_loads_server(registry, factory))
main.mount(create_analysis_server(registry, factory))
main.mount(create_project_server(registry, factory))
# 4. Toolset 필터링
if settings.toolsets != "all":
_apply_toolset_filter(main, settings.toolsets)
# 5. Read-only 모드
if settings.read_only:
main.disable(tags={"write"}, components={"tool"})
return main
GennxApiClient의 생명주기는 FastMCP의 lifespan으로 관리합니다. 서버가 살아있는 동안 커넥션 풀을 재사용하고, 종료 시 close()가 호출되어 내부 httpx 클라이언트의 aclose()가 보장됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
@asynccontextmanager
async def app_lifespan(server: FastMCP):
settings = GennxSettings()
client = GennxApiClient(
settings.gennx_api_base_url,
settings.gennx_api_timeout,
settings.gennx_mapi_key,
)
try:
yield {"api_client": client, "settings": settings}
finally:
await client.close()
tool 함수 내부에서는 ctx.lifespan_context["api_client"]로 클라이언트를 꺼내 씁니다. 159개 tool이 하나의 클라이언트 인스턴스를 공유하면서도 각자 독립된 클로저로 동작합니다.
4. MCP 클라이언트-서버 동작 흐름
4.1 초기 핸드셰이크
MCP 클라이언트(Claude Desktop, Claude Code, Cursor 등)가 서버에 연결되면 initialize → list_tools 순서로 요청을 보냅니다. 연결 시 한 번만 일어납니다.
서버가 돌려주는 것은 두 가지입니다.
(1) Tool 정의 목록 — 활성화된 toolset(기본값 default)에 해당하는 약 87개 tool의 메타데이터입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
{
"name": "post_db_node",
"title": "Create Node",
"description": "Create nodes (절점) - define geometry points in 3D space in GEN NX. ...",
"inputSchema": {
"type": "object",
"properties": {
"Assign": {
"type": "object",
"additionalProperties": { "type": "object", "properties": {
"X": {"type": "number"}, "Y": {"type": "number"}, "Z": {"type": "number"}
}}
}
},
"required": ["Assign"]
},
"annotations": { "readOnlyHint": false, "destructiveHint": false, "idempotentHint": false }
}
(2) Server instructions — MCP 프로토콜의 InitializeResult.instructions 필드입니다. 서버가 tool 사용 방법에 대한 힌트를 자유 텍스트로 넘깁니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# src/mcp_gennx/server.py
INSTRUCTIONS = """\
GEN NX MCP Server - Structural Engineering Analysis
...
Typical workflow:
1. Create nodes (post_db_node) to define geometry
2. Create elements (post_db_elem) to connect nodes
3. Define materials (post_db_matl) and sections (post_db_sect)
4. Apply boundary conditions (post_db_cons)
5. Define load cases (post_db_stld) and apply loads (post_db_cnld, post_db_bmld)
6. Run analysis (post_doc_anal)
...
"""
main = FastMCP("gennx", instructions=INSTRUCTIONS, lifespan=app_lifespan)
클라이언트는 이 instructions를 받아서 시스템 프롬프트에 병합합니다. LLM은 사용자 메시지를 보기 전부터 “GEN NX 작업은 보통 노드 → 요소 → 재료 → 경계 → 하중 → 해석 순서로 진행된다”는 워크플로 힌트를 이미 가지고 있는 상태가 됩니다.
4.2 매 턴마다 전달되는 것
MCP 서버에 list_tools를 다시 요청하는 건 아니지만, LLM API 호출에는 매 턴 tool 정의 전체가 포함됩니다. LLM API가 stateless이기 때문입니다. 이건 이 서버만의 특성이 아니라 모든 MCP 서버에 공통된 구조입니다.
1
2
3
4
5
6
MCP 서버 ──(한 번)──→ 클라이언트가 tool 목록 캐싱
│
├─ Turn 1: LLM API(tools=[87개], messages=[...])
├─ Turn 2: LLM API(tools=[87개], messages=[...])
├─ Turn 3: LLM API(tools=[87개], messages=[...])
└─ ...
한 턴에 LLM이 받는 것을 풀어 그리면 다음과 같습니다.
1
2
3
4
5
6
7
8
[ LLM API 요청 1회 ]
├─ system: server instructions + 클라이언트 기본 system prompt
├─ tools: [87개 tool 정의] ← 매 턴 동일하게 포함
└─ messages:
[user] "3경간 연속보를 만들고 자중 적용해서 고유치해석 돌려줘"
[assistant] (이전 턴 응답 — tool_use 포함)
[user] (이전 턴 tool_result — 서버가 반환한 JSON)
... 누적 ...
87개와 159개의 차이는 대화 한 턴당 수천 토큰의 고정 비용 차이로 직결됩니다. toolset 필터링이 필요한 이유입니다.
참고로 Anthropic API의 prompt caching 기능을 쓰면, tool 배열이 매 턴 동일하므로 Turn 2부터는 ~90% 할인된 비용으로 처리됩니다. Claude Desktop, Claude Code 등 공식 클라이언트는 이를 자동 적용합니다.
4.3 반응형 루프
LLM은 사전에 전체 계획을 세워놓고 순서대로 실행하는 것이 아닙니다. 한 스텝 실행 → 결과 확인 → 다음 스텝 결정을 반복하는 반응형(reactive) 루프입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
[Turn 1]
LLM 입력: system(+instructions) + tools[87] + user 메시지
LLM 출력: tool_use 블록 1~N개
예) post_db_node(Assign={"1":{"X":0,"Y":0,"Z":0}, ..., "4":{"X":15,...}})
post_db_matl(Assign={"1":{...}}) ← 한 턴에 병렬 호출 가능
post_db_sect(Assign={"1":{...}})
↓ MCP 클라이언트가 각 tool_use를 서버에 전달
↓ 서버가 GennxApiClient로 GEN NX REST 호출
↓ tool_result를 LLM에 돌려줌
[Turn 2]
LLM 입력: 위 전부 + tool_result들
LLM 출력: 결과 확인 후 다음 tool_use
예) post_db_elem(Assign={"1":{"TYPE":"BEAM","MATL":1,"SECT":1,"NODE":[1,2]}, ...})
[Turn 3~N]
post_db_cons → post_db_stld → post_db_bodf → post_db_eigv → post_doc_anal
중요한 점 세 가지입니다:
- 병렬 호출: Claude Sonnet 4+ / Opus 4+는 한 응답에 여러
tool_use블록을 낼 수 있습니다. 독립적인 작업(노드 생성 + 재료 정의 + 단면 정의)은 한 턴에 묶입니다. - 계획 변경:
post_db_elem이 에러를 돌려주면, LLM은 그 자리에서 순서를 바꾸거나 재시도합니다.GennxApiClient는 타임아웃·연결 실패·HTTP 4xx/5xx를ToolError로 변환해서 돌려주므로, LLM은 에러 메시지를 읽고 대응할 수 있습니다. - 모호한 요청: 경간 길이, 단면 종류 등이 명시되지 않으면 LLM이 기본값을 가정하거나 사용자에게 되묻습니다.
4.4 LLM의 분해 재료
“3경간 연속보 + 자중 + 고유치해석”이라는 요청이 노드·요소·재료·경계·하중·해석 순서의 tool 호출로 분해되는 것은 세 가지 재료의 조합 덕분입니다.
| 재료 | 역할 | 예시 |
|---|---|---|
| 모델의 훈련 데이터 (도메인 지식) | “3경간 연속보 = 4절점 + 3보 요소”, “자중 = body force” | 이 지식이 없는 도메인이면 분해 자체가 불가능 |
서버 instructions의 워크플로 힌트 | “노드 → 요소 → 재료 → …” 순서를 텍스트로 제공 | LLM이 tool과 단계를 매칭하는 근거 |
| tool 이름·description·예제 payload | post_db_node, post_db_bodf, post_db_eigv 등 | 훈련 데이터의 구조해석 API 관례와 겹침 |
셋 중 하나라도 빠지면 — 예를 들어 instructions를 비우거나, tool 이름을 api_7f3b_create처럼 불투명하게 짓거나 하면 — 분해 정확도가 눈에 띄게 떨어집니다. 결국 MCP 서버의 품질은 서버가 제공하는 두 축, instructions와 tool 메타데이터의 품질에 크게 좌우됩니다.
4.5 tool 수와 정확도
매 턴마다 tool 메타데이터 전체가 컨텍스트에 포함되므로, tool을 많이 노출할수록 두 가지 문제가 커집니다.
- Context 비용: 87개 = 수천 토큰, 159개 = 그 두 배. 대화가 길어질수록 누적됩니다.
- 선택 노이즈:
db/CONS(지점 조건)와db/CNLD(절점 하중)처럼 이름이 유사한 tool이 동시에 노출되면 LLM이 혼동합니다.
이 서버는 기본값으로 87개만 노출하고, 필요 시 TOOLSETS=all로 159개를 켭니다. 구현은 5장에서 다룹니다.
5. 구현 원리
65개의 JSON 스키마 파일이 런타임에 46개의 엔드포인트로 인덱싱되고, 각 엔드포인트의 HTTP method마다 독립된 MCP tool이 생성되어 최대 159개의 tool이 노출됩니다. 별도의 코드 생성(codegen) 단계 없이, JSON 파일만 추가/수정하고 서버를 재기동하면 끝입니다.
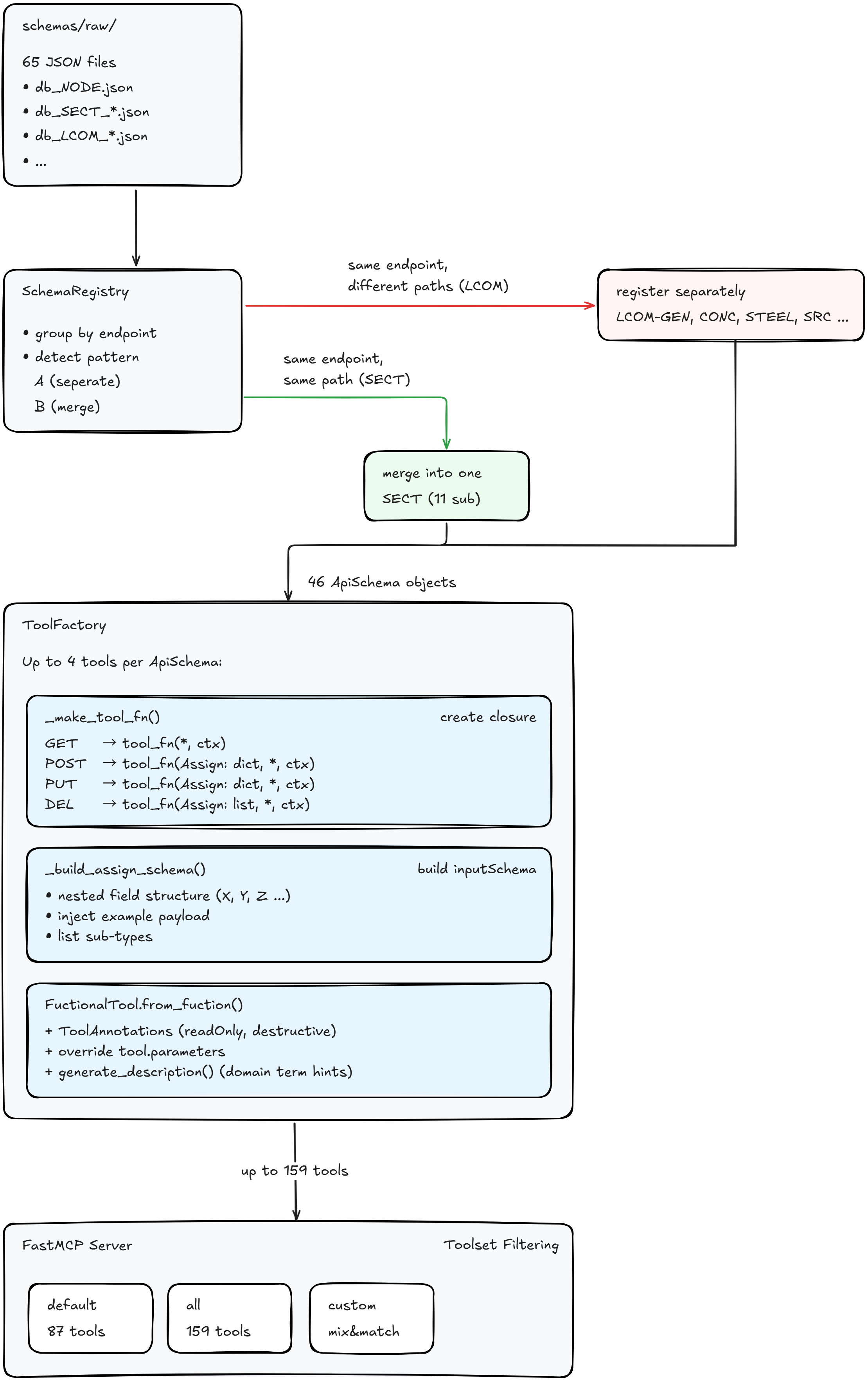
5.1 Schema Registry — 스키마 로드와 병합
SchemaRegistry가 schemas/raw/ 디렉토리의 65개 JSON 파일을 endpoint 필드 기준으로 그룹핑합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# src/mcp_gennx/schemas/registry.py
def _load_all(self, schema_dir: Path) -> None:
endpoint_files: dict[str, list[tuple[Path, dict]]] = {}
for path in sorted(schema_dir.glob("*.json")):
data = json.loads(path.read_text(encoding="utf-8"))
endpoint = data.get("endpoint", "")
if not endpoint:
continue
endpoint_files.setdefault(endpoint, []).append((path, data))
for endpoint, items in endpoint_files.items():
if len(items) == 1:
self._load_single(items[0][1])
else:
self._load_multi(endpoint, items)
파일명이 아니라 JSON 내부의 endpoint 필드로 그룹핑합니다. GEN NX 스키마에서 하나의 논리적 엔드포인트가 여러 파일로 쪼개져 있는 경우가 있기 때문입니다.
하나의 엔드포인트에 여러 JSON 파일이 묶였을 때, 두 가지 패턴이 혼재합니다.
- 패턴 A — 경로가 다른 sub-type: 하중조합(LCOM)은
db/LCOM-GEN,db/LCOM-CONC,db/LCOM-STEEL등 6개의 독립된 API 경로를 가집니다. → 6개 tool로 분리 - 패턴 B — 경로가 같은 sub-type: 단면(
db/SECT)은 11개 sub-type이 있지만 API 경로는 하나입니다. → 1개 tool로 병합
구분 기준은 input_uri 필드에서 뽑아낸 실제 API 경로의 개수입니다.
1
2
3
4
5
6
7
8
9
def _load_multi(self, endpoint: str, items: list[tuple[Path, dict]]) -> None:
api_paths = set()
for _, data in items:
api_paths.add(_extract_api_path(data))
if len(api_paths) > 1:
self._load_multi_separate(endpoint, items) # LCOM: 6개 분리
else:
self._load_multi_merged(endpoint, items) # SECT: 1개 병합
5.2 ToolFactory — 클로저 패턴
ToolFactory는 각 HTTP method마다 서로 다른 시그니처의 비동기 함수를 클로저로 생성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
# src/mcp_gennx/tools/factory.py
def _make_tool_fn(self, endpoint: str, method: str):
if method == "GET":
async def tool_fn(*, ctx: Context) -> str:
client = ctx.lifespan_context["api_client"]
result = await client.get(endpoint)
return json.dumps(result, ensure_ascii=False, indent=2)
elif method == "DELETE":
async def tool_fn(Assign: list, *, ctx: Context) -> str:
client = ctx.lifespan_context["api_client"]
result = await client.delete(endpoint, {"Assign": Assign})
return json.dumps(result, ensure_ascii=False, indent=2)
else: # POST, PUT
async def tool_fn(Assign: dict, *, ctx: Context) -> str:
client = ctx.lifespan_context["api_client"]
result = await client.request(method, endpoint, {"Assign": Assign})
return json.dumps(result, ensure_ascii=False, indent=2)
tool_fn.__name__ = f"{method.lower()}_{endpoint.replace('/', '_').lower()}"
return tool_fn
| Method | 시그니처 | 의도 |
|---|---|---|
| GET | get_db_node(*, ctx) | 파라미터 없이 읽기 |
| POST | post_db_node(Assign: dict, *, ctx) | ID-keyed dict로 생성 |
| PUT | put_db_node(Assign: dict, *, ctx) | ID-keyed dict로 갱신 |
| DELETE | delete_db_node(Assign: list, *, ctx) | ID 리스트로 삭제 |
하나의 범용 함수가 method를 인자로 받는 방식 대신, method별로 시그니처를 다르게 만듭니다. LLM이 함수 시그니처만 보고도 의도를 파악할 수 있게 하기 위함입니다.
추가로 ToolAnnotations로 메타데이터를 붙입니다.
1
2
3
4
5
annotations=ToolAnnotations(
readOnlyHint=(method == "GET"),
destructiveHint=(method == "DELETE"),
idempotentHint=(method in ("GET", "PUT")),
)
destructiveHint=True인 tool은 Claude Desktop 같은 클라이언트에서 사용자에게 확인을 요청합니다.
5.3 예제를 description에 주입
_build_assign_schema()는 원본 JSON Schema를 LLM이 이해하기 쉬운 parameter schema로 변환합니다. 엔드포인트의 스키마 구조에 따라 5가지로 분기합니다:
- 엔드포인트명과 일치하는 단일 최상위 키 — NODE, ELEM, MATL 등 대부분의 db/* API.
additionalProperties로 ID-keyed dict 구조를 평탄화합니다. SECT(17개)·THIK(4개)도 sub-type 파일들이 모두 동일한 최상위 키("SECT"/"THIK")를 사용하므로 registry에서 병합된 뒤 이 분기로 합류합니다. - 다중 최상위 키 —
$schema+Argument를 함께 가진db/STOR같은 경우. sub-type 목록을 description에 텍스트로 명시합니다. $schema가 최상위 —doc/*API의Argument패턴. 이미 표준 JSON Schema 형태이므로 그대로 passthrough합니다. 다만doc/*7개는project.py에서 데코레이터로 수동 등록되므로, 현재 이 분기는 실질적으로 안전망 역할입니다.- 엔드포인트명과 불일치하는 단일 키 —
db/LCOM엔드포인트 아래"LCOM-GEN","LCOM-CONC"등 6개 sub-type이 여기에 해당합니다. 1번과 동일한 평탄화를 적용합니다. - 최종 폴백 — 빈 object schema 반환. 현재 65개 스키마 중 이 분기로 빠지는 것은 없고, 스키마 작성 오류에 대비한 안전망입니다.
가장 효과가 큰 부분은 예제 payload를 description에 JSON으로 주입하는 것입니다.
1
2
3
example = _get_first_example(schema.examples)
if example:
desc += f" Example: {json.dumps(example, ensure_ascii=False)}"
JSON Schema만 제공하면 LLM이 필드 구조는 파악하지만 실제 값을 채울 때 자주 틀립니다. 특히 {"1": {...}, "2": {...}} 같은 ID-keyed dict의 키 관례(정수 문자열)는 additionalProperties만으로는 표현이 안 됩니다. 예제 한 줄을 description에 붙이는 것만으로 올바른 payload 생성 비율이 크게 올라갑니다. 현재 구현은 분기 1·2에만 예제 주입 로직이 들어있고, LCOM 계열(분기 4)에는 누락되어 있어 보강 여지가 있습니다.
5.4 tool 등록 — 일반적인 MCP 패턴과 다른 점
다른 MCP 서버들이 tool을 등록하는 일반적인 방법부터 살펴보고, GEN NX가 왜 다른 접근을 택했는지 설명합니다.
일반적인 MCP tool 등록 패턴
JavaScript/TypeScript (Atlassian MCP 등) — inputSchema를 JSON으로 직접 작성합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
// mcp-atlassian의 실제 tool 정의 (jira/tools.js)
{
name: 'search_issues_by_user_involvement',
description: 'Search for issues based on how a specific user is involved...',
inputSchema: {
type: 'object',
properties: {
username: { type: 'string', description: 'The username to search for.' },
searchType: { type: 'string', enum: ['assignee', 'reporter', 'creator', 'watcher', 'all'] },
maxResults: { type: 'number', default: 50, minimum: 1, maximum: 100 },
},
required: ['searchType'],
},
}
파라미터가 username: string, searchType: enum, maxResults: number 같은 flat한 스칼라 값들입니다. 각 필드의 type, description, enum, default를 직접 기술하면 됩니다.
Python (FastMCP) — 같은 역할을 Annotated/Field와 ToolAnnotations로 표현합니다.
1
2
3
4
5
6
7
8
9
10
11
12
from typing import Annotated
from pydantic import Field
@server.tool(
annotations=ToolAnnotations(readOnlyHint=True),
)
async def search_issues_by_user_involvement(
search_type: Annotated[str, Field(description="Type of user involvement")],
username: Annotated[str | None, Field(description="The username to search for")] = None,
max_results: Annotated[int, Field(description="Max issues to return", ge=1, le=100)] = 50,
) -> str:
...
FastMCP는 이 함수 시그니처를 Pydantic TypeAdapter에 넘겨서 자동으로 inputSchema JSON Schema를 생성합니다. Annotated[str, Field(description=...)]의 description은 inputSchema.properties.*.description이 되고, Field(ge=1, le=100)은 minimum/maximum이 됩니다.
이 두 방식 — JS의 직접 JSON Schema 기술이든, Python의 Annotated/Field든 — 모두 파라미터가 flat하고 tool 수가 제한적일 때 잘 동작합니다. Atlassian MCP는 약 40개의 tool을 이 방식으로 하나하나 정의합니다.
GEN NX에서 이 패턴이 어려운 이유
GEN NX의 Assign 파라미터는 flat한 스칼라 값이 아닙니다. ID-keyed dict 안에 중첩된 object입니다.
1
2
3
4
5
6
{
"Assign": {
"1": {"X": 0, "Y": 0, "Z": 0},
"2": {"X": 5, "Y": 0, "Z": 0}
}
}
이걸 Annotated/Field로 표현하면:
1
2
3
4
async def post_db_node(
Assign: Annotated[dict, Field(description="Node data keyed by ID")]
) -> str:
...
이게 전부입니다. Annotated[dict, Field(...)]만으로는 다음 정보를 inputSchema에 담을 수 없습니다:
additionalProperties의 내부 필드 구조 (각 value가X: number, Y: number, Z: number속성을 가진 object라는 것)- 예제 payload (
{"1": {"X": 0, "Y": 0, "Z": 0}}) - SECT의 sub-type 목록 (
Available sub-types: STEEL, PSC, COMPOSITE, ...)
Field(description=...)은 flat한 텍스트 하나를 받을 뿐이고, additionalProperties 안의 중첩된 properties까지 표현하려면 46개 엔드포인트마다 각각 다른 Pydantic 모델을 정의해야 합니다. 여기에 스케일 문제가 겹칩니다. 46개 엔드포인트 x 최대 4개 HTTP method = 159개 tool을 수동으로 정의하는 건 Atlassian MCP의 40개와 차원이 다릅니다.
GEN NX의 해법 — parameters 오버라이드
ToolFactory는 FunctionTool.from_function()으로 tool을 생성한 뒤, Pydantic이 자동 생성한 빈약한 inputSchema를 원본 JSON Schema 기반의 풍부한 schema로 덮어쓰는 방식을 씁니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
# src/mcp_gennx/tools/factory.py
tool = FunctionTool.from_function(
fn, # _make_tool_fn()이 만든 클로저
name=tool_def.tool_name,
description=tool_def.description,
annotations=ToolAnnotations(
readOnlyHint=(method == "GET"),
destructiveHint=(method == "DELETE"),
idempotentHint=(method in ("GET", "PUT")),
),
)
# 핵심: Pydantic이 자동 생성한 빈약한 schema를,
# 원본 JSON Schema에서 만든 풍부한 schema로 덮어쓴다
tool.parameters = tool_def.parameters_schema
server.add_tool(tool)
_build_assign_schema()가 원본 JSON Schema에서 뽑아낸 결과물은 이런 모양입니다:
1
2
3
4
5
6
7
8
9
10
11
12
{
"type": "object",
"description": "Node data keyed by ID. Example: {\"1\":{\"X\":0,\"Y\":0,\"Z\":0}}",
"additionalProperties": {
"type": "object",
"properties": {
"X": {"type": "number", "description": "GLOBAL X-POSITION"},
"Y": {"type": "number", "description": "GLOBAL Y-POSITION"},
"Z": {"type": "number", "description": "GLOBAL Z-POSITION"}
}
}
}
Annotated[dict, Field(description="...")]이었다면 {"type": "object"}로 끝났을 schema가, 오버라이드를 통해 필드별 type과 description, 예제 payload, sub-type 정보까지 갖춘 형태가 됩니다.
| Atlassian MCP (일반적 패턴) | GEN NX ToolFactory | |
|---|---|---|
| 파라미터 구조 | flat 스칼라 (string, number, enum) | 중첩 dict (ID → {X, Y, Z, ...}) — 엔드포인트마다 내부 필드가 다름 |
inputSchema 정의 | JS: 직접 JSON / Python: Annotated/Field | 원본 JSON Schema → tool.parameters 오버라이드. 내부 필드 구조를 additionalProperties.properties로 표현 |
| tool 수 | ~40개 (수동 정의 가능한 규모) | ~152개 (수동 정의 비현실적 → JSON Schema에서 동적 생성) |
ToolAnnotations | 미사용 | method별 자동 부여 (readOnly, destructive, idempotent) |
| 확장 방법 | 코드에 tool 정의 추가 | JSON 파일 추가 + ENDPOINTS dict 한 줄 |
project sub-server — 데코레이터 방식이 적합한 경우
한편 doc/* API들은 Assign 패턴을 따르지 않습니다. 파라미터가 아예 없거나(doc/NEW, doc/SAVE), 문자열 하나(doc/OPEN의 file_path: str), 또는 선택적 dict(doc/ANAL의 Argument: dict | None)처럼 단순합니다. 이런 경우에는 일반적인 데코레이터 패턴이 오히려 적합합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# src/mcp_gennx/servers/project.py
@server.tool(
name="post_doc_anal",
description="Run structural analysis in GEN NX. ...",
tags={"project", "write", "toolset:project"},
annotations=ToolAnnotations(
readOnlyHint=False, destructiveHint=False, idempotentHint=False
),
)
async def post_doc_anal(Argument: dict | None = None, *, ctx: Context) -> str:
client = ctx.lifespan_context["api_client"]
payload = {"Argument": Argument} if Argument else {}
result = await client.post("doc/ANAL", payload)
return json.dumps(result, ensure_ascii=False, indent=2)
이 방식에서는 ToolAnnotations를 데코레이터에 전달하고, 함수 시그니처의 Python type hint(Argument: dict | None = None)가 FastMCP에 의해 자동으로 inputSchema로 변환됩니다.
project sub-server에서 db/UNIT과 db/STYP만 ToolFactory를 경유하고, 나머지 7개(post_doc_anal, post_doc_new, post_doc_open, post_doc_save, post_doc_saveas, post_doc_close, post_view_capture)는 데코레이터로 직접 등록합니다.
tool-level description — 도메인 용어 힌트
inputSchema와 별개로, LLM이 tool을 선택할 때 보는 tool-level description은 utils/descriptions.py의 generate_description()이 생성합니다. description은 영문 기반이지만, 한국어 도메인 용어를 괄호로 함께 기재합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
# src/mcp_gennx/utils/descriptions.py
FEATURE_DESCRIPTIONS = {
"db/NODE": "nodes (절점) - define geometry points in 3D space",
"db/ELEM": "elements (요소) - connect nodes to form structural members",
"db/CONS": "boundary conditions (지점조건) - define supports and constraints",
"db/EIGV": "eigenvalue analysis parameters (고유치해석) - set modal analysis options",
...
}
def generate_description(schema: ApiSchema, method: str) -> str:
verb = METHOD_VERBS.get(method, method) # POST → "Create"
feature = FEATURE_DESCRIPTIONS.get(schema.api_path) or ...
return f"{verb} {feature} in GEN NX. ..."
결과적으로 post_db_node의 description은 "Create nodes (절점) - define geometry points in 3D space in GEN NX. Provide data in the Assign parameter." 형태가 됩니다. 영어 description이 기본이라 글로벌 LLM에서 잘 동작하면서, 괄호 안의 한국어 용어 덕분에 “절점 만들어줘” 같은 한국어 요청에도 tool 매칭 정확도가 올라갑니다.
5.5 Toolset 필터링
모든 tool은 생성 시 세 종류의 태그를 부여받습니다: domain 태그(modeling, boundary, …), access 태그(read, write), toolset 태그(toolset:modeling_core 등).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
# src/mcp_gennx/server.py
TOOLSET_DEFINITIONS: dict[str, list[str]] = {
"default": [
"modeling_core", "boundary_core", "loads_core",
"analysis_core", "project",
],
"all": [
"modeling_core", "modeling_advanced",
"boundary_core", "boundary_advanced",
"loads_core", "loads_advanced",
"analysis_core", "analysis_advanced",
"project",
],
}
def _apply_toolset_filter(server: FastMCP, toolsets_config: str) -> None:
enabled_toolsets = _resolve_toolsets(toolsets_config)
enabled_tags = {f"toolset:{ts}" for ts in enabled_toolsets}
for tag in DOMAIN_TAGS:
server.disable(tags={tag}, components={"tool"})
for tag in enabled_tags:
server.enable(tags={tag}, components={"tool"})
환경 변수 하나로 노출 tool 수가 바뀝니다.
1
2
3
4
5
TOOLSETS=default # 87개 — core만 (기본값)
TOOLSETS=all # 159개 — advanced 포함
TOOLSETS=default,loads_advanced # 87 + 고급 하중 타입
TOOLSETS=modeling_core # 모델링 core 20개만
READ_ONLY=true # write 태그 전부 OFF
태그만 올바르게 붙여두면 새 엔드포인트를 추가할 때 필터링 로직을 수정할 필요가 없습니다. JSON 파일을 추가하고 sub-server의 ENDPOINTS dict에 한 줄 등록하면 끝입니다.
6. 정리
| 주제 | 요약 |
|---|---|
| MCP 동작 | 클라이언트는 연결 시 한 번 list_tools + instructions를 받고, LLM API 호출마다 tool 리스트 전체를 재전송합니다 (LLM API가 stateless이므로). prompt caching으로 Turn 2+ 비용은 ~90% 감소합니다. |
| 반응형 루프 | 사전 계획이 아니라 한 스텝 실행 → 결과 확인 → 다음 결정의 반복입니다. 한 턴에 병렬 호출 가능하고, 실패 시 순서를 변경합니다. |
| 분해 재료 | (a) 모델의 도메인 지식 + (b) 서버 instructions + (c) tool 이름·description·예제. 셋 중 하나가 빠지면 분해 정확도가 떨어집니다. |
| 동적 생성 | 65 JSON → 46 엔드포인트 → 최대 159 tool. codegen 없이 런타임 생성합니다. LCOM은 분리, SECT는 병합합니다. |
| tool 등록 | 일반적 MCP 패턴(Annotated/Field 또는 직접 JSON)은 flat 파라미터에 적합합니다. GEN NX는 중첩 dict + 159개 스케일 때문에, ToolFactory가 원본 JSON Schema에서 tool.parameters를 동적 오버라이드합니다. 단순한 doc/* API 7개만 데코레이터 방식을 씁니다. |
| Toolset 필터링 | 태그 기반 enable/disable. 기본 87개, 전체 159개, 환경 변수로 전환합니다. |
앞으로 해볼 것
- 나머지 GEN NX API 커버 (해석 결과 조회, 설계 검토 등)
- instructions 고도화 — tool 간 의존관계, 도메인 용어 사전, 자주 발생하는 오류 패턴 등을 보강하여 LLM의 tool 사용 정확도를 높이는 방향
- tool description을 JSON 스키마 파일로 통합 — 현재
descriptions.py에 하드코딩된 description을 각 JSON 스키마 파일의feature_description필드로 옮겨서, 스키마와 description이 한 파일에서 관리되도록 개선 listChanged기반 동적 tool 로딩 — 초기에는 project tools만 노출하고, 필요 시 도메인별 toolset을 런타임에 활성화
참고
- 프로젝트 저장소: github.com/Gabriel-Hong/mcp-gennx
- Model Context Protocol: modelcontextprotocol.io
- FastMCP: github.com/jlowin/fastmcp
- GEN NX: midasit.com