Do Transformers Need Three Projections? — QKV 투영을 공유해 KV 캐시를 절반으로
논문: Do Transformers Need Three Projections? Systematic Study of QKV Variants
저자: Ali Kayyam, Anusha Madan Gopal, M Anthony Lewis (BrainChip Inc., Laguna Hills, CA)
발표: arXiv:2606.04032v2 · ICML 2026 (PMLR 306)
코드: github.com/Brainchip-Inc/Do-Transformers-Need-3-Projections
핵심 키워드: QKV projection sharing, weight tying, KV cache reduction, GQA/MQA, low-rank attention, edge deployment
핵심 요약
Transformer 어텐션은 매 토큰을 Query·Key·Value 세 개의 선형 투영으로 변환하는 것이 표준입니다. 그런데 이 세 투영이 정말 모두 필요한가? 이 논문은 투영을 묶어버리는(weight tying) 세 가지 공유 변형을 합성·비전·언어모델 12개 과제에 걸쳐 체계적으로 비교합니다.
결론은 명확합니다. K와 V를 묶는 Q-K=V 구성은 표준 QKV와 거의 동등한 품질을 유지하면서 KV 캐시를 정확히 50% 줄입니다(300M 모델 기준 perplexity +3.1%, 1.2B 기준 +2.48%). 더 중요한 건, 이 투영 공유가 GQA/MQA 같은 head sharing과 직교(orthogonal) 하다는 점입니다 — 둘을 곱해서 결합하면 Q-GQA-4는 87.5%, Q-MQA는 96.9% 캐시 절감에 도달해 온디바이스 추론이 현실이 됩니다.
| 변형 | 어텐션 식 | 투영 수 | KV 캐시 | 비대칭성 | 한 줄 평 |
|---|---|---|---|---|---|
| QKV (기준) | $\mathrm{Softmax}(\alpha QK^\top)V$ | 3 | 기준 | ✅ | 표준 |
| Q=K-V | $\mathrm{Softmax}(\alpha KK^\top)V$ | 2 | 0% 절감 | ❌ 대칭 | 학습은 좋으나 캐시 이득 없음 → 배포 부적합 |
| Q-K=V | $\mathrm{Softmax}(\alpha QK^\top)K$ | 2 | 50% 절감 | ✅ | 실용적 승자 |
| Q=K=V | $\mathrm{Softmax}(\alpha KK^\top)K$ | 1 | 50% 절감 | ❌ 대칭 | 너무 공격적, LLM에선 품질 붕괴 |
헤드라인 숫자 (300M GPT, SlimPajama 10B 토큰):
| 구성 | PPL 저하 vs QKV | KV 캐시 절감 | 비고 |
|---|---|---|---|
| Q-K=V | +3.1% | 50% | 투영 공유 단독 최선 |
| GQA-4 | +0.7% | 75% | head sharing |
| MQA | +1.5% | 93.8% | head sharing |
| Q-GQA-4 | +3.9% | 87.5% | 투영×head 결합 |
| Q-MQA | +4.8% | 96.9% | 가장 공격적 |
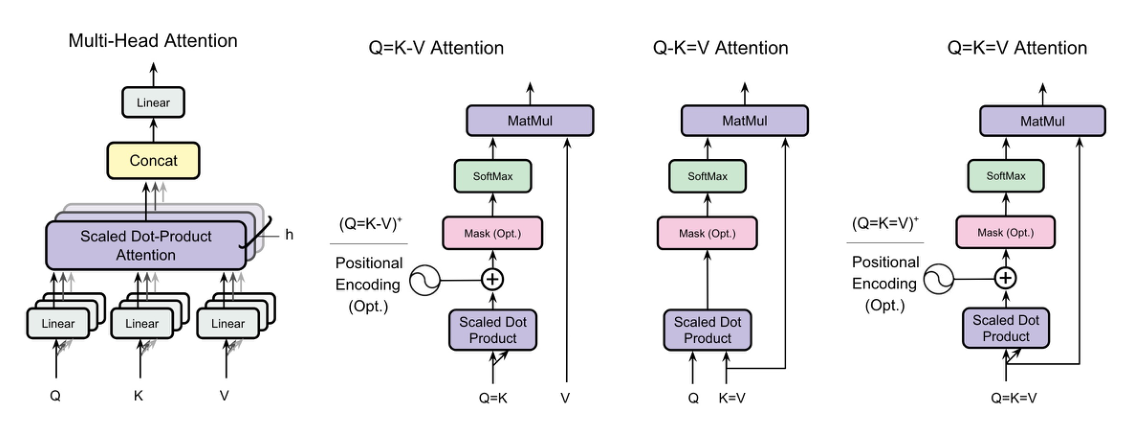
Figure 1. 제안하는 Projection-Shared Attention 변형들. 좌: 표준 Multi-Head Attention(Q·K·V 각각 별도 Linear). 이후 셋: Q=K-V(Q와 K를 통합, V는 분리), Q-K=V(K와 V를 통합, Q는 분리), Q=K=V(셋을 하나로).
(X)+는 2D positional encoding으로 대칭성을 깨는 변형으로, $Q=K$에서 발생하는 대칭 어텐션 맵에 방향성을 주입한다.
1. 서론 — 세 개의 투영은 정말 필요한가
Transformer(Vaswani et al., 2017)는 언어를 넘어 멀티모달 AI의 backbone이 되었지만, 컨텍스트 길이가 길어지고 실시간 추론 수요가 커지면서 연구의 초점은 구조적 효율성으로 옮겨갔습니다. Performer·Linformer 같은 선형 복잡도 모델부터 Ring Attention·blockwise 기법까지, 대부분은 self-attention의 $O(n^2)$ 병목을 겨냥합니다.
그런데 더 근본적인 질문이 남아 있습니다 — Query·Key·Value라는 3분할 투영 자체가 꼭 필요한가? CNN이나 현대 State Space Model(SSM)은 훨씬 통합된 내부 표현을 쓰는데, Transformer만 유독 투영 행렬들 사이에 지속적인 중복(redundancy) 을 유지합니다. 저자들은 이를 검증하기 위해 세 가지 Projective Sharing 구조를 제안합니다.
- Q=K-V: Q와 K를 통합, V는 분리
- Q-K=V: Q는 분리, K와 V를 통합
- Q=K=V: 셋 모두 단일 투영
핵심 발견은 투영 행렬 수를 줄이면 파라미터와 연산이 줄면서도 다운스트림 성능 저하는 최소이며, 그 효과가 과제 의존적이라는 것입니다.
2. 세 가지 투영 공유 변형
표준 단일 헤드 어텐션은 입력 $X \in \mathbb{R}^{n\times d}$에 대해 다음을 계산합니다.
\[A_h = \mathrm{Softmax}\!\left(\alpha\, Q_h K_h^\top\right) V_h, \qquad Q_h = XW_q,\; K_h = XW_k,\; V_h = XW_v\]여기서 $\alpha = 1/\sqrt{d_k}$는 스케일 인자, $d_k = d/H$, $H$는 헤드 수입니다. 어텐션 점수 $QK^\top$가 토큰 쌍의 친화도를 인코딩합니다.
2.1 Q=K-V — 대칭 어텐션과 그 한계
Q와 K를 묶으면($Q=K$) 어텐션이 다음 형태가 됩니다.
\[A = \mathrm{Softmax}\!\left(\alpha\, KK^\top\right) V\]문제는 $KK^\top$가 대칭 행렬이라는 점입니다. 그래프 신경망·관계 추론에서는 방향 편향이 없는 게 유리할 수 있지만, 인과 의존성이 필요한 순차 과제에는 제약이 됩니다. 저자들은 이를 보완하기 위해 (Q=K-V)+ 를 도입합니다 — 고정 2D 사인 positional encoding $P \in \mathbb{R}^{n\times n\times m}$을 어텐션 점수에 더한 뒤 $1\times1$ convolution으로 다시 $n\times n$ 맵으로 투영해 방향성(asymmetry)을 복원합니다(부록 A.2).
2.2 Q-K=V — 실용적 승자
Key와 Value를 통합($V=K$)하되 Q는 독립으로 둡니다.
\[A = \mathrm{Softmax}\!\left(\alpha\, QK^\top\right) K\]$Q$와 $K$가 여전히 독립이므로 어텐션 맵의 비대칭성이 보존됩니다. “Key와 Value가 표현을 공유한다”는 제약은 언어모델링에서 효과가 입증된 weight tying(Press & Wolf, 2017)의 일종으로 볼 수 있습니다. 그리고 결정적으로, $V$를 따로 캐싱할 필요 없이 $K$를 재사용하므로 KV 캐시가 절반이 됩니다.
2.3 Q=K=V — 가장 공격적인 단순화
세 역할을 단일 투영으로 합칩니다.
\[A = \mathrm{Softmax}\!\left(\alpha\, KK^\top\right) K\]variant 1의 대칭성과 variant 2의 표현 병목을 동시에 갖습니다. 대칭성 완화를 위해 (Q=K=V)+ 도 함께 평가합니다.
(X)+ 변형의 적용 범위: 2D positional encoding은 $Q=K$의 대칭성이 주된 한계가 되는 비인과(non-causal) 설정(비전, 합성 과제)을 위한 것입니다. 인과 언어모델링은 이미 causal mask로 비대칭성을 강제하므로,
(X)+는 그곳에서 굳이 필요 없습니다 — 따라서 비인과 과제에만 적용하고 보편적 보강이 아닌 과제별 휴리스틱으로 취급합니다.
3. Head Sharing과의 직교적 결합
이 논문의 가장 실용적인 통찰은 투영 공유가 GQA/MQA 같은 head sharing과 다른 축에서 작동한다는 점입니다.
- Head sharing: 여러 query 헤드가 소수의 KV 헤드를 공유. GQA-$g$는 $H$개 query 헤드가 $g<H$개 KV 헤드를 공유하고, MQA는 단 하나의 KV 헤드를 모든 query가 공유하는 극단입니다.
- Projection sharing: 한 헤드 안에서 $K=V$ 제약을 거는 것.
둘은 서로 다른 차원을 건드리므로 곱셈적으로 결합됩니다.
- Q-GQA-$g$: 각 GQA 그룹 안에 $K=V$ 적용 → 캐시 절감 $1 - \dfrac{g}{2H}$
- Q-MQA: MQA에 $K=V$ 적용 → 가장 공격적
연산·파라미터 복잡도는 다음과 같습니다(어텐션 점수 계산 $O(n^2 d)$는 모든 변형 공통이라 제외).
| 변형 | 연산량 | 파라미터 |
|---|---|---|
| QKV | $3nd^2$ | $3d^2$ |
| Q=K-V / Q-K=V | $2nd^2$ | $2d^2$ |
| (Q=K-V)+ | $2nd^2 + n^2 m$ | $2d^2 + m$ |
| Q=K=V | $nd^2$ | $d^2$ |
| (Q=K=V)+ | $nd^2 + n^2 m$ | $d^2 + m$ |
2-투영 변형은 투영 연산이 $3nd^2 \to 2nd^2$로 33% 감소하고, Q=K=V는 1/3 수준입니다. 단, self-attention 투영은 전체 Transformer 파라미터의 ~30%에 불과해 파라미터 절감 자체는 작습니다 — 진짜 이득은 다음에 볼 추론 메모리에 있습니다.
4. 실험 결과
모든 모델은 동일 하이퍼파라미터로 from-scratch 학습(set anomaly만 사전학습 ResNet34 feature 사용)합니다. 목표는 SOTA가 아니라 어텐션 구조 차이의 통제된 비교입니다.
4.1 합성 과제
길이가 정해진 0–9 숫자 리스트에 대한 다섯 과제 — Reverse / Sort / Sub(9에서 빼기) / Swap(전·후반 교환) / Copy. 단일 Transformer 인코더로 토큰별 예측.
| REVERSE | SORT | SUB | SWAP | COPY | Avg | |
|---|---|---|---|---|---|---|
| QKV | 0.698 | 0.971 | 1.0 | 0.588 | 1.0 | 0.851 |
| Q=K-V | 0.705 | 0.967 | 1.0 | 0.597 | 1.0 | 0.854 |
| (Q=K-V)+ | 0.718 | 0.963 | 1.0 | 0.671 | 1.0 | 0.870 |
| Q-K=V | 0.701 | 0.958 | 1.0 | 0.590 | 1.0 | 0.850 |
| Q=K=V | 0.514 | 0.939 | 1.0 | 0.446 | 1.0 | 0.780 |
| (Q=K=V)+ | 0.581 | 0.957 | 1.0 | 0.576 | 1.0 | 0.823 |
2D positional encoding을 더한 (Q=K-V)+ 가 QKV를 능가합니다(특히 방향성이 중요한 Swap에서). 반면 단일 투영 Q=K=V는 대칭성 때문에 뒤처지지만, +를 붙이면 상당 부분 회복됩니다.
4.2 비전 과제
| MNIST | FMNIST | CIFAR-10 | CIFAR-100 | TinyImgNet | Anomaly | Avg | |
|---|---|---|---|---|---|---|---|
| QKV | 0.981 | 0.887 | 0.663 | 0.363 | 0.229 | 0.942 | 0.767 |
| Q=K-V | 0.981 | 0.885 | 0.666 | 0.369 | 0.236 | 0.954 | 0.771 |
| (Q=K-V)+ | 0.982 | 0.884 | 0.662 | 0.366 | – | 0.966 | 0.772 |
| Q-K=V | 0.976 | 0.883 | 0.659 | 0.358 | – | 0.949 | 0.767 |
| Q=K=V | 0.978 | 0.877 | 0.672 | 0.376 | 0.266 | 0.933 | 0.767 |
흥미롭게도 ViT 기반 TinyImageNet에서는 단일 투영 Q=K=V가 최고 정확도(0.266) 를 내며, epoch당 학습 시간도 40→35→32분으로 짧습니다. 비대칭성이 덜 중요한 이미지 분류에서는 투영을 줄여도 손해가 거의 없다는 신호입니다.
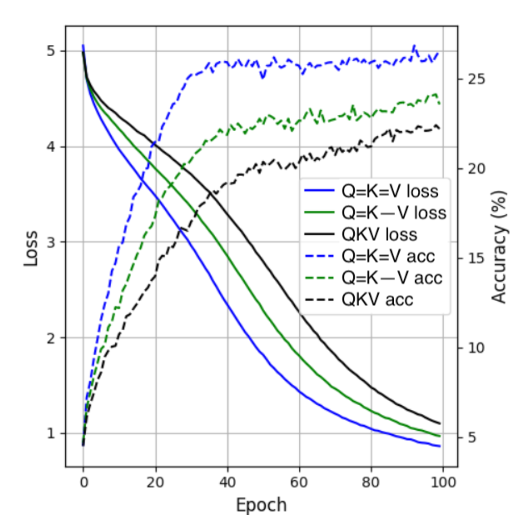
Figure 2. TinyImageNet 분류의 학습 손실(실선)과 검증 정확도(점선). 단일 투영 Q=K=V(파랑)가 가장 낮은 손실과 가장 높은 정확도에 도달하며, Q=K-V(초록)·QKV(검정)와 큰 격차 없이 경쟁한다 — 비인과 비전 과제에서는 투영 공유가 거의 무손실임을 보여준다.
4.3 언어모델 — 핵심 결과
SlimPajama 10B 토큰으로 GPT 스타일 300M·1.2B 모델을 from-scratch 학습합니다(어텐션 투영만 다르고 나머지는 동일).
| 구성 | Train PPL | Val PPL | 속도(tok/s) | PPL 저하 | 캐시 절감 |
|---|---|---|---|---|---|
| QKV (기준) | 5.64 | 5.11 | 423k | — | — |
| Q-K=V | 5.58 | 5.27 | 427k | +3.1% | 50% |
| Q=K-V | 5.66 | 5.36 | 440k | +4.9% | 0% |
| Q=K=V | 7.23 | 6.41 | 460k | +25.4% | 50% |
| GQA-4 | 5.58 | 5.15 | 435k | +0.7% | 75% |
| MQA | 5.59 | 5.19 | 448k | +1.5% | 93.8% |
| Q-GQA-4 | 5.64 | 5.32 | 442k | +3.9% | 87.5% |
| Q-MQA | 5.66 | 5.36 | 455k | +4.8% | 96.9% |
세 가지 교훈이 나옵니다.
- Q-K=V가 투영 공유의 승자 — +3.1% perplexity로 50% 캐시 절감. 학습 내내 기준선을 바짝 추적.
- Q=K-V는 함정 — 학습 품질은 Q-K=V보다 약간 나쁜 정도(+4.9%)지만, $V$를 분리 캐싱해야 해서 캐시 이득이 0%. 실배포에는 부적합합니다.
- Q=K=V는 LLM엔 과함 — 단일 투영 제약이 너무 강해 +25.4% perplexity로 품질이 붕괴. (비전과 정반대 결과 — 과제 의존성이 핵심.)
4.4 KV 캐시 — 진짜 이득
| 모델 | 캐시 항목 | 토큰당 | @32K | 절감 |
|---|---|---|---|---|
| QKV (기준) | K + V | 80 KB | 2.62 GB | — |
| Q=K-V | K + V | 80 KB | 2.62 GB | 0% |
| Q-K=V | K only | 40 KB | 1.31 GB | 50% |
| GQA-4 | K + V | 20 KB | 0.66 GB | 75% |
| MQA | K + V | 5 KB | 0.16 GB | 93.8% |
| Q-GQA-4 | K only | 10 KB | 0.33 GB | 87.5% |
| Q-MQA | K only | 2.5 KB | 0.08 GB | 96.9% |
캐시 절감은 곧 같은 메모리로 2배 긴 컨텍스트, 2배 높은 처리량(동시 사용자), 메모리 병목 서비스에서 40–50% 비용 절감을 의미합니다. 컨텍스트가 길어질수록 어텐션이 전체 연산에서 차지하는 비중이 커지므로(4096 토큰에서 50% 초과) 이 이득은 더 커집니다.
4.5 1.2B 스케일 & 다운스트림
| 모델 | PPL | 저하 | 파라미터(M) | 캐시(MB) |
|---|---|---|---|---|
| QKV | 5.004 | — | 1,215 | 5,900 |
| Q-K=V | 5.128 | +2.48% | 1,123 | 2,950 |
| GQA-8 | 5.030 | +0.52% | 1,077 | 1,408 |
| MQA | 5.057 | +1.06% | 1,036 | 176 |
| Q-MQA | 5.212 | +4.16% | 1,033 | 88 |
스케일이 커지면 상대적 순위가 안정적으로 유지될 뿐 아니라 격차가 더 좁아집니다(Q-K=V는 300M의 +3.1% → 1.2B의 +2.48%). MQA는 +1.06%로 QKV와 사실상 동등하면서 97% 캐시 절감.
더 중요한 건 perplexity 격차가 다운스트림 성능으로 잘 전이되지 않는다는 점입니다. 5-shot 벤치마크(HellaSwag·PIQA·ARC-E/C·WinoGrande) 평균에서 Q-K=V는 QKV 대비 단 −0.41%(35.99% vs 36.40%)에 그칩니다. 즉 추론 메모리 절감이 실제 과제 능력의 손실 없이 따라옵니다. Q-GQA-8은 오히려 기준을 살짝 넘기도 합니다(36.72%).
5. 왜 Q-K=V는 되고 Q=K-V는 안 되나
겉보기엔 둘 다 “투영 하나를 묶은” 2-투영 변형인데 운명이 갈립니다. 핵심은 어텐션의 방향성(directionality) 입니다.
- Q-K=V가 품질을 보존하는 이유: Key와 Value는 비슷한 표현 공간을 점유할 수 있고, 어텐션은 보통 저랭크(low-rank) 영역에서 작동합니다. 그래서 $K=V$로 묶어도 표현력 손실이 작습니다. 또한 $QK^\top$를 그대로 계산하므로 표준 Transformer의 off-diagonal 어텐션 분포가 보존됩니다.
- Q=K-V가 실패하는 이유: $Q=K$는 $KK^\top$라는 대칭 어텐션을 낳아 방향성을 파괴합니다. 게다가 대칭 어텐션은 각 토큰이 자기 자신에 강하게 주목하는 대각 우세(diagonal dominance) 문제를 일으키는데, 대각 정규화나 softmax 온도 조절로도 일관된 개선이 어려웠습니다.
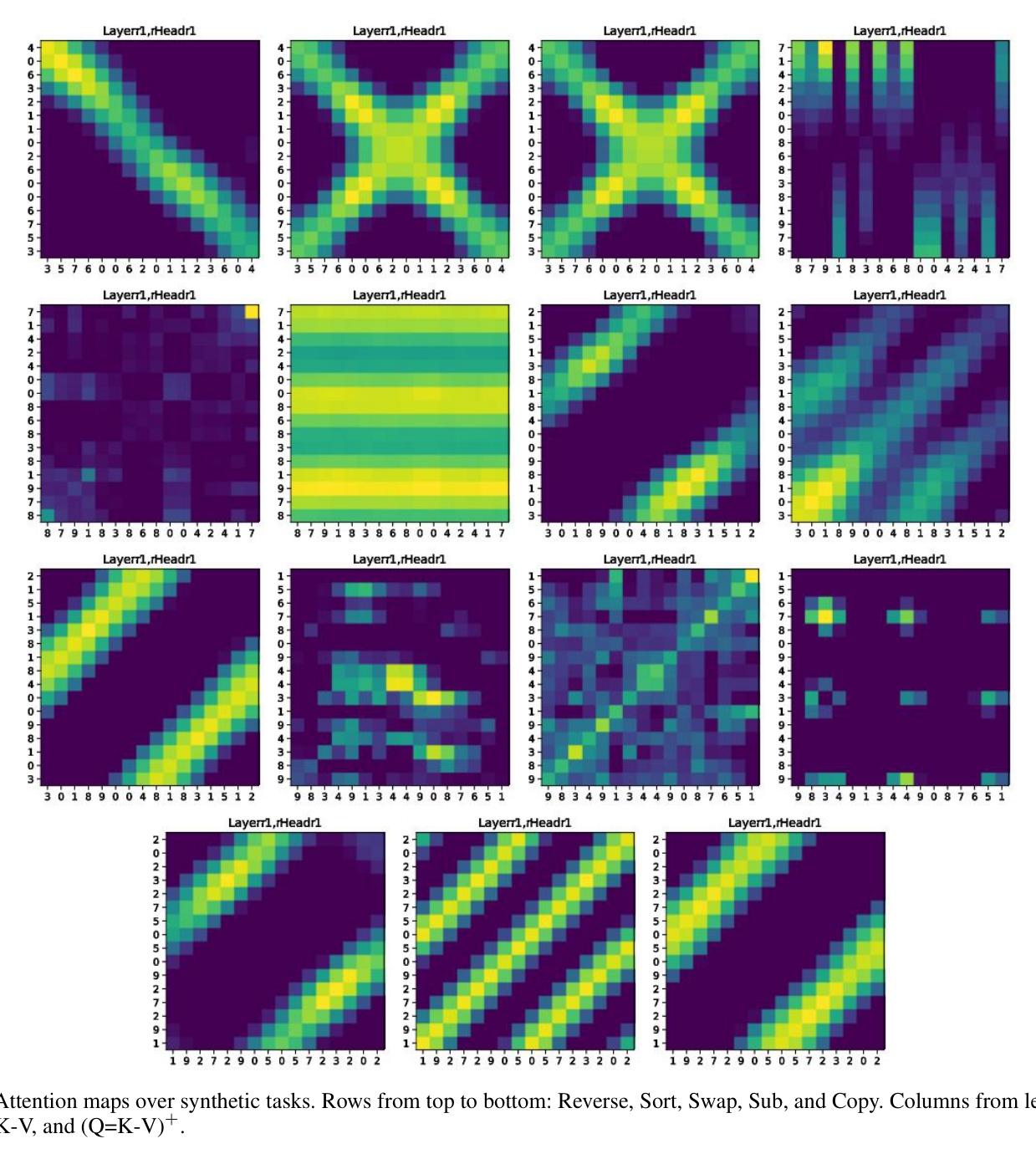
Figure 3. 합성 과제(위→아래: Reverse, Sort, Swap, Sub, Copy)의 어텐션 맵, 열은 QKV / Q=K-V / (Q=K-V)+. Q=K-V(가운데 열)의 맵은 $y=x$ 직선을 기준으로 대칭임이 뚜렷하다 — Q와 K를 묶으면서 방향성이 사라진 결과다. 예컨대 Reverse 과제에서 QKV는 뒤집힌 인덱스 토큰에 (느슨하게) 주목하는 패턴을 학습한다.
6. QKV Collapse → Linear Attention = SSM (부록 A.1)
세 표현을 하나로 합치는($q_t = k_t = v_t = z_t$, $z_t = Wx_t$) 극단을 취하면 흥미로운 이론적 통일이 드러납니다. 커널(선형) 어텐션은 softmax를 양의 feature map $\phi(\cdot)$로 대체하는데, collapse를 대입하면 다음 재귀식이 됩니다.
\[S_t = \sum_{i\le t} \phi(z_i) z_i^\top, \qquad y_t = \frac{\phi(z_t)^\top S_t}{\phi(z_t)^\top \sum_{i\le t}\phi(z_i)}\]상태 $S_t$는 자기 자신의 outer-product를 누적하며, 증분 갱신(선택적 decay $\lambda$ 포함)으로 표현됩니다.
\[S_t = \lambda S_{t-1} + \phi(z_t) z_t^\top\]토큰–토큰 상호작용 행렬을 전혀 만들지 않고 스트리밍 상태 갱신 + 국소 readout만으로 진행됩니다. 이는 고전적 이산 SSM
\[h_t = A h_{t-1} + B x_t, \qquad y_t = C h_t\]과 직접 대응됩니다 — $S_t$가 은닉 상태, outer-product 항이 입력 의존 갱신, decay가 안정적 전이 연산자 역할을 합니다. 차이는 어텐션이 입력 조건부 readout $y_t = \phi(z_t)^\top S_t$를 쓴다는 점뿐입니다. 즉 선형 어텐션은 “적응적(content-dependent) 관측”을 가진 SSM의 특수형이며, 이것이 선형 어텐션과 현대 SSM이 유사한 스케일링·스트리밍 특성을 공유하는 이유를 설명합니다.
7. 배포 권장 & 결론
저자들은 자원 제약별 권장 구성을 제시합니다.
| 시나리오 | 권장 구성 | 캐시 절감 | ΔPPL |
|---|---|---|---|
| Cloud (품질 우선) | GQA-4 | 75% | +0.7% |
| Edge (균형) | Q-K=V | 50% | +3.1% |
| Edge (공격적) | Q-GQA-4 | 87.5% | +3.9% |
| IoT/Mobile | Q-MQA | 96.9% | +4.8% |
| 학습 자원 제약 | Q-K=V | 50% | +3.1% |
핵심 메시지를 정리하면:
- Q-K=V는 유일하게 실배포 이점이 있는 2-투영 변형입니다. 50% 캐시 절감을 품질 손실 거의 없이 얻습니다.
- Q=K-V는 피하라 — 학습 품질이 좋아 보여도 캐시 이득이 0이라 프로덕션엔 무의미.
- 투영 공유는 head sharing과 직교하므로 GQA/MQA와 곱해 edge·온디바이스 추론까지 밀어붙일 수 있습니다.
- 효과는 과제 의존적 — 비인과 비전에선 단일 투영(Q=K=V)도 통하지만, 인과 LLM에선 K=V(Q-K=V)가 한계선입니다.
요컨대 이 연구는 투영 공유를 어텐션에서 잘 탐구되지 않은 weight tying 사례로 자리매김하고, 정량적인 추론 메모리 이득과 함께 그것이 언제·왜 통하는지를 체계적으로 규명합니다.
부록 — 핵심 수식 정리
① 표준 어텐션:
\[A_h = \mathrm{Softmax}\!\left(\alpha\, Q_h K_h^\top\right) V_h, \qquad \alpha = 1/\sqrt{d_k}\]② 세 가지 투영 공유 변형:
\[\underbrace{\mathrm{Softmax}(\alpha KK^\top)V}_{\text{Q=K-V}}, \qquad \underbrace{\mathrm{Softmax}(\alpha QK^\top)K}_{\text{Q-K=V}}, \qquad \underbrace{\mathrm{Softmax}(\alpha KK^\top)K}_{\text{Q=K=V}}\]③ Head×Projection 결합 캐시 절감: Q-GQA-$g$ → $1 - \dfrac{g}{2H}$
④ QKV collapse 시 선형 어텐션 재귀:
\[S_t = \lambda S_{t-1} + \phi(z_t) z_t^\top, \qquad y_t = \frac{\phi(z_t)^\top S_t}{\phi(z_t)^\top \sum_{i\le t}\phi(z_i)}\]⑤ 대응하는 SSM:
\[h_t = A h_{t-1} + B x_t, \qquad y_t = C h_t\]한 줄 정리
“세 개의 투영 중 하나는 묶어도 된다 — 단, 올바른 하나를.” Key와 Value를 묶는 Q-K=V는 어텐션 방향성을 지키면서 KV 캐시를 50% 줄이고, GQA/MQA와 직교 결합해 최대 96.9% 캐시 절감까지 도달한다. 반대로 Q와 K를 묶는 Q=K-V는 대칭성에 발목이 잡혀 캐시 이득이 0이다. perplexity 격차는 다운스트림으로 거의 전이되지 않아, 투영 공유는 엣지·온디바이스 LLM을 위한 실용적 weight tying이 된다.
References
- Kayyam, Madan Gopal, Lewis. Do Transformers Need Three Projections? Systematic Study of QKV Variants. arXiv:2606.04032 · ICML 2026 — 본 논문 · 코드
- Vaswani et al. Attention Is All You Need. NeurIPS 2017 — 표준 QKV 어텐션
- Ainslie et al. GQA: Training Generalized Multi-Query Transformer Models. EMNLP 2023 — Grouped Query Attention
- Shazeer. Fast Transformer Decoding: One Write-Head Is All You Need. (2019) — Multi-Query Attention
- Press & Wolf. Using the Output Embedding to Improve Language Models. EACL 2017 — weight tying
- Katharopoulos et al. Transformers Are RNNs: Fast Autoregressive Transformers with Linear Attention. ICML 2020 — 선형 어텐션 재귀
- Gu & Dao. Mamba: Linear-Time Sequence Modeling with Selective State Spaces. (2023) — SSM
- Pope et al. Efficiently Scaling Transformer Inference. MLSys 2023 — KV 캐시 병목
- Gao et al. The Language Model Evaluation Harness. (2024) — 다운스트림 5-shot 평가