Contexts are Never Long Enough: Structured Reasoning for Scalable Question Answering over Long Document Sets
논문: Contexts are Never Long Enough: Structured Reasoning for Scalable Question Answering over Long Document Sets
프로젝트: sliders.genie.stanford.edu
코드: github.com/stanford-oval/sliders
저자: Harshit Joshi, Priyank Shethia, Jadelynn Dao, Monica S. Lam (Stanford OVAL Lab, Computer Science Department)
발표일: 2026년 4월 24일 (arXiv:2604.22294v1, cs.CL)
핵심 키워드: long-document QA, structured reasoning, schema induction, data reconciliation, text-to-SQL, provenance, aggregation bottleneck
핵심 요약
SLIDERS(Scalable Long-document Integration through Decomposed Extraction and Reconciliation System)는 Stanford OVAL Lab이 제안한 장문서 집합에 대한 질의응답(QA) 프레임워크입니다. 핵심 아이디어는 “정보의 표현”과 “추론”을 분리하는 것 — 비정형 문서를 관계형 데이터베이스(RDB) 로 추출한 뒤, SQL을 통해 추론하여 컨텍스트 윈도우 한계 자체를 우회합니다. 특히 chunk 기반 RAG/Agent가 chunk 수 증가에 따라 다시 long-context 문제를 만드는 “Aggregation Bottleneck“을 정면 돌파합니다.
| 구분 | 기존 (RAG, GraphRAG, RLM, GPT-4.1 직접 등) | SLIDERS |
|---|---|---|
| 중간 표현 | 비정형 텍스트(요약/chunk 출력) | 관계형 DB (스키마 + provenance + rationale) |
| 추론 방식 | LLM이 거대한 텍스트를 다시 읽음 | LLM이 SQL을 작성·실행 |
| 확장성 | 100만 토큰 이상에서 정확도 급락 | 36M 토큰까지 일정 정확도 유지 |
| 정확도 (3 기존 벤치 평균) | GPT-4.1 68.69 | 75.56 (+6.6pt) |
| WikiCeleb100 (3.9M) | 차상위 RLM 59.80 | 78.91 (+19.1pt) |
| FinQ100 (36M) | 차상위 LongRAG 28.87, RLM($2000 추정) | 55.22, $34에 실행 |
| 감사가능성 | 자유 형식 출력 → 검증 곤란 | 모든 행에 provenance·rationale 저장 → SQL 감사 가능 |
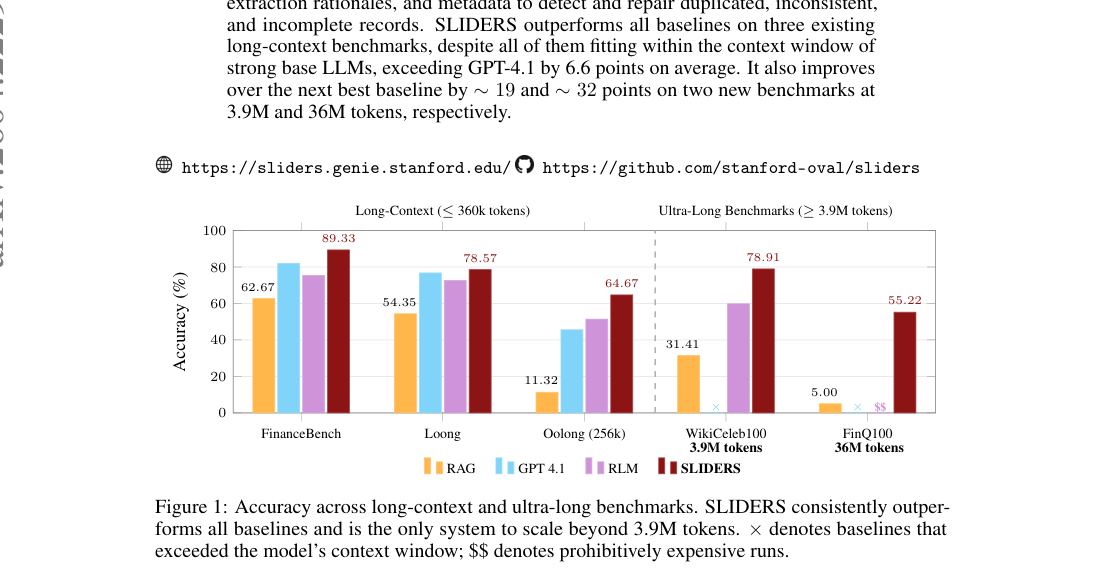
Figure 1. ×는 컨텍스트 윈도우 초과로 실행 불가, $$는 비용상 실행 불가를 의미합니다. SLIDERS는 3.9M 토큰을 넘어 스케일 가능한 유일한 시스템입니다.
1. 서론 — 왜 긴 문서 QA가 어려운가
1.1 실세계의 문서 분석 문제
금융 · 의료 · 사회과학 등 지식 집약 분야의 분석가는 다수 문서, 한 문서의 여러 섹션에 흩어진 증거를 종합해야 합니다. 예를 들어 SEC 10-Q 분기보고서 100건을 모아 “어떤 회사가 장기차입금이 가장 낮은가?”를 묻는다면, 모든 문서를 읽고 비교하고 정규화해야 합니다.
현재 LLM은 백만 토큰 컨텍스트 윈도우를 가지지만 다음 한계가 있습니다.
- 현실 corpus 크기 > 윈도우 크기: 실제 분석 대상은 종종 수천만 토큰
- 분산된 증거 통합 실패: 멀리 떨어진 섹션·문서 간 정보를 결합하는 데 약함 (Liu et al. 2023, Hsieh et al. 2024)
- 자유형 출력의 감사 곤란: 고위험 의사결정에 사용 시 검증·규제 대응 불가
- 추론 비용 폭증: ultra-long context 추론은 경제성·지연 측면에서 비현실적
1.2 Aggregation Bottleneck — Chunking의 함정
가장 널리 채택되는 우회법은 문서를 잘라 chunk 단위로 답을 만들고 합치는 방식(RAG, Chain of Agents, DocETL 등)입니다. Chunking은 컨텍스트 한도를 피하고 국소 디테일에 집중하게 해주지만, chunk가 늘어날수록 결국 chunk별 출력의 합본을 다시 LLM이 읽어야 한다는 새로운 long-context 문제가 생깁니다. 본 논문은 이를 “Aggregation Bottleneck” 이라 부릅니다.
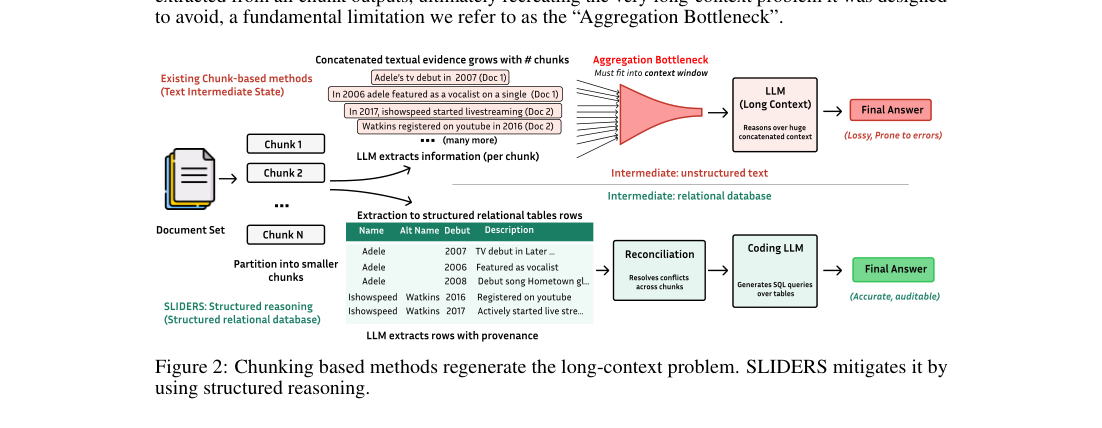
Figure 2. 위쪽 — 기존 방식은 chunk별 텍스트 결과를 LLM 컨텍스트에 다시 합쳐 추론. 아래쪽 — SLIDERS는 chunk 결과를 관계형 테이블로 적재한 뒤 SQL로 질의해 텍스트 합본 자체가 필요 없음.
1.3 본 논문의 기여
| 기여 | 내용 |
|---|---|
| 개념 | Aggregation Bottleneck 정의, “정보 표현 ↔ 추론”의 분리 원칙 제시 |
| 시스템 | SLIDERS — 5단계 파이프라인 (Chunking · Schema Induction · Structured Extraction · Reconciliation · SQL QA) |
| 알고리즘 | Provenance·rationale·메타데이터를 1급 신호로 사용하는 첫 Reconciliation Agent |
| 벤치마크 | WikiCeleb100(3.9M tokens, 100개 위키), FinQ100(36M tokens, 100개 10-Q) 신규 공개 |
| 결과 | 기존 long-context 벤치 평균 +6.6pt, ultra-long 벤치에서 차상위 대비 +19~50pt |
2. SLIDERS 개요
질문 $q$와 장문서 집합 $D$가 주어졌을 때, SLIDERS는 비정형 텍스트를 전역적으로 일관된 데이터베이스로 변환한 후 그 위에서 SQL로 추론합니다.
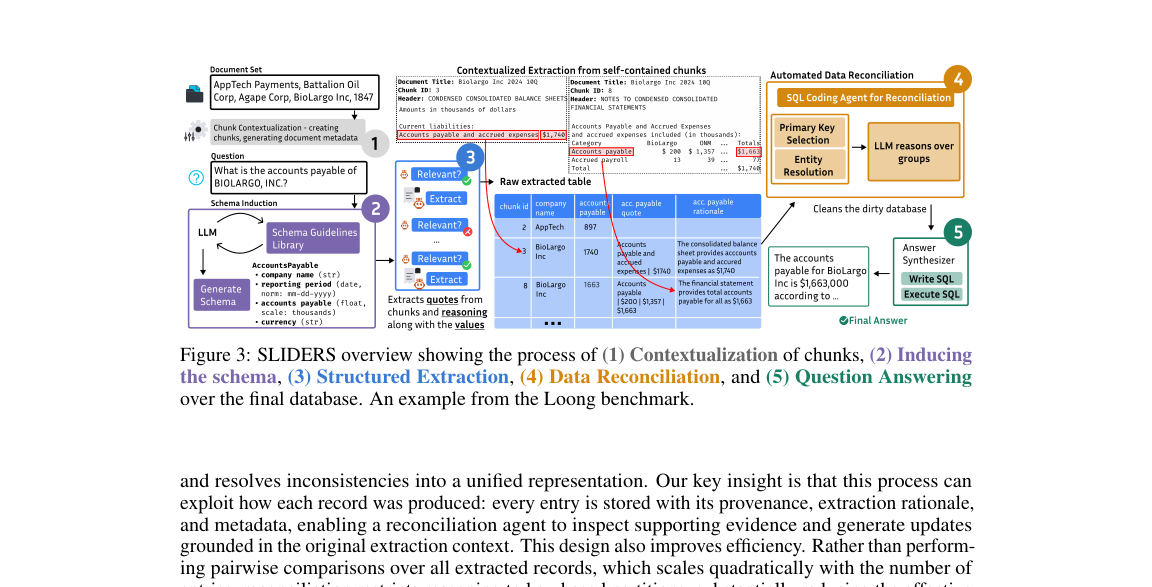
Figure 3. (1) Chunk Contextualization → (2) Schema Induction → (3) Structured Extraction (relevance gate + provenance/rationale 추출) → (4) Data Reconciliation (SQL Coding Agent) → (5) Answer Synthesizer (SQL 생성·실행).
2.1 세 가지 연구 질문과 5가지 태스크
| 연구 질문 | 해결 태스크 |
|---|---|
| RQ1: 추출 시 전역 컨텍스트를 보존하기 위해 어떻게 문서를 분해할 것인가? | ① Contextualized Chunking — 메타데이터 $M$ 기반 chunk 생성 |
| RQ2: 원문 질문 답변에 필요한 모든 정보를 보존하는 관계형 표현을 어떻게 만들 것인가? | ② Schema Induction — $q, M \rightarrow$ 스키마 $S$ ③ Structured Extraction — $D, M, S \rightarrow$ 테이블 $T$ |
| RQ3: 부분·중복·충돌하는 추출 결과를 어떻게 일관된 글로벌 DB로 만들고 답변할 것인가? | ④ Data Reconciliation — $T \rightarrow T’$ (정합화된 테이블) ⑤ Question Answering — $T’$ 위에서 SQL 반복 생성·실행 |
2.2 왜 작동하는가 (직관)
- 저장 = 압축: 비정형 텍스트를 정형 행으로 옮기면 동일 정보가 훨씬 작아짐. corpus 크기에 무관하게 컴팩트.
- 추론 = 쿼리: 집계·비교·산술 같은 LLM의 약점 연산을 RDB의 결정적 연산으로 오프로드.
- 감사 = provenance: 모든 셀에 출처 chunk와 추출 근거 텍스트가 함께 저장되어 사람·에이전트가 즉시 검증 가능.
- 저장된 표현은 재사용: 같은 corpus에 대한 후속 질문은 추출 비용 없이 SQL만 새로 생성.
3. Contextualized Extraction
3.1 Contextualized Chunking — 자가 충족적 청크
LLM이 chunk 하나만 보고도 올바르게 추출할 수 있도록, 각 문서 $d \in D$에 메타데이터 $m = (m^G_d, m^L_d)$를 부착하고 청킹합니다.
| 메타데이터 종류 | 내용 |
|---|---|
| 전역 (Global) $m^G_d$ | 자동 생성한 문서 제목, 문서 수준 요약 — 모든 chunk가 공유 |
| 로컬 (Local) $m^L_d$ | 섹션 헤더, 표, 그림 캡션 같은 구조적 신호 — 자연스러운 레이아웃 경계와 정렬 |
이렇게 풍부해진 표현을 사용해 단락·표·코드·캡션을 가르지 않으면서 청크를 자른 뒤, 각 청크에 문서 ID, 페이지 인덱스, 구조 태그를 부착합니다. 결과적으로 각 chunk는 로컬 자가 충족적이 됩니다.
3.2 Schema Induction — 질문에서 관계 스키마로
자유형 추출과 달리 RDB는 엄격한 스키마를 요구합니다. 또한 자유형 출력은 다형성(예: $75°F$ vs $24°C$) 때문에 SQL 집계가 불가능합니다. 이를 해결하기 위해 SLIDERS는 질문 $q$와 문서 메타데이터 $M$에서 task-specific 스키마를 유도합니다.
Definition 1 (Schema Induction). 출력 스키마 $S = \{S_1, S_2, \ldots, S_k\}$, 테이블 스키마 $S = \langle sn, f_1, \ldots, f_n\rangle$, 그리고 필드는
\[f = \langle fn,\, d,\, \tau,\, u,\, \sigma,\, \rho\rangle\]| 기호 | 의미 |
|---|---|
| $fn$ | 필드명 |
| $d$ | 의미적 텍스트 설명 |
| $\tau$ | 데이터 타입 (int, str, float, date, …) |
| $u$ | 단위 (USD, kg, …) |
| $\sigma$ | 스케일 (millions, thousands, …) |
| $\rho$ | 정규화 규칙 (통화 변환, 날짜 포맷 등) |
스키마 라이브러리: LLM이 먼저 (a) 질문 유형 — Ordering, Multiple Choice, Others — 과 (b) 문서 유형 — Narration, Policy, Dataset, Others — 을 분류한 뒤, 해당 카테고리의 가이드라인을 조회해 스키마를 작성합니다.
3.3 Relevance Gate — 환각 억제 장치
엄격한 타입을 강요하는 schema는 역설적으로 관련 정보가 없는 chunk에서 환각을 유발합니다 (모델이 형식 준수를 강제받아 없는 값을 만들어냄). SLIDERS는 추출 전에 Relevance Gate를 둡니다 — chunk가 schema 엔티티와 관련된 증거를 포함하는지 LLM이 먼저 판단하고, 통과한 chunk만 추출합니다.
검증 결과: 20개 오답에서 샘플링한 516개 chunk 중 282개가 gate에서 거부되었고, false negative는 단 1개(0.4%). gate는 주요 오류 원인이 아니며, 대부분의 실패는 schema 불일치나 reconciliation에서 발생합니다.
3.4 Structured Extraction — Provenance가 1급 시민
Definition 2 (Structured Extraction). 입력 $(q, D, M, S)$에서 행 집합 $T = \{T_1, \ldots, T_k\}$를 생성. 각 셀은
\[e_f = \langle v,\, p,\, r\rangle\]| 요소 | 의미 |
|---|---|
| $v$ | 단위·스케일 정규화된 값 |
| $p$ | Provenance — 값을 뒷받침하는 최소 텍스트 span |
| $r$ | Rationale — quote를 값으로 매핑한 결정 근거 |
전체 추출은 다음과 같이 정의됩니다.
\[SE(q, D, M, S) = \bigcup_{c \in d,\, d \in D} \widetilde{SE}(\tilde{q}, c, m, S)\] \[\widetilde{SE}(\tilde{q}, c, m, S) = \begin{cases} SE^{LLM}(\tilde{q}, c, m, S) & \text{if } R(\tilde{q}, c, m, S) \\ \emptyset & \text{otherwise} \end{cases}\]- $R(\cdot)$ 은 명시적 relevance gate
- $\tilde{q}$ 는 질문 $q$를 추출 작업용으로 변형한 것
- $\bigcup$ 은 중복 제거 없는 union (중복은 이후 reconciliation에서 처리)
- 추출은 in-context learning + JSON 출력으로 구현
왜 확장 가능한가
| 이유 | 설명 |
|---|---|
| Unbounded corpus | 분석 단위가 단일 chunk이므로 corpus 크기에 비례한 작업으로 분해 |
| Parallelism | gate · 추출이 chunk 간 독립 → 완전 병렬화 |
4. Data Reconciliation — 핵심 기여
4.1 왜 필요한가
문서들은 동일 정보를 여러 섹션에서 분산·반복·정련합니다. 예) 위키 article은 인트로에서 출생일과 주 직업을 언급한 뒤 나중 섹션에서 부가 직업을 다룸. 각 chunk 추출은 국소적으론 옳지만 합산하면 누락·중복·충돌이 발생합니다. Reconciliation은 이를 하나의 일관된 글로벌 상태로 정합화합니다.
Definition 3 (Data Reconciliation). $T = SE(q, D, M, S)$ 를 입력받아 정합화된 $T’ = \{T’_1, \ldots, T’_k\}$ 생성.
4.2 핵심 관찰 — 관계 구조가 자연 분해를 준다
순진하게 모든 행을 쌍별 비교하면 행 수의 제곱에 비례. 그러나 같은 엔티티/주장에 관한 진술들은 공통 식별 속성(=primary key)으로 묶임. PK로 행을 그룹핑하면 작은 의미적 그룹 안에서만 정합화하면 됩니다. 또한 추출 시 함께 저장된 provenance, rationale, 문서 메타데이터를 그룹별로 가져다 쓸 수 있습니다.
4.3 Algorithm 1 — Data Reconciliation
| 단계 | 의사코드 |
|---|---|
| Init | $q^r \leftarrow$ adapt $q$ for reconciliation |
| Phase 1: Partitioning | for each table $T_i \in T$: $pk_i \leftarrow$ SELECT_PRIMARY_KEY($T_i, q^r$) //doc-level then table-level $T_i \leftarrow$ RESOLVE_PRIMARY_KEY_ENTITIES($T_i, pk_i$) $G_i \leftarrow$ GROUP_BY_PRIMARY_KEY($T_i, pk_i$) |
| Phase 2: Reconciliation Agent | for each $T_i$, for each group $g \in G_i$ in parallel: loop: $op \leftarrow$ SELECT_RECON_OP($g, q^r$) if $op = \emptyset$: break $sql \leftarrow$ RECONCILE_GROUP($g, op$) $g \leftarrow$ APPLY($sql, g$) |
| Non-PK ER | $T’_i \leftarrow$ RESOLVE_NON_PRIMARY_KEY_ENTITIES($\{g\}, pk_i$) |
| return | $T’$ |
4.4 Phase 1 세부 — Partitioning
Primary Key 선택. LLM에 (1) reconciliation용으로 변형한 질문 $q^r$, (2) 테이블 스키마, (3) rationale이 붙은 추출 행 샘플을 제공해 PK 열(들)을 선택. 3회 호출 후 majority voting으로 견고성 강화.
Primary Key 값의 Entity Resolution. “J. Smith”, “John Smith”, “Smith, John”이 동일 인물임을 정렬. 절차:
- 문서 내 ER (열 하나씩) — semantic equivalence 프롬프트로 blocking. 문서 간 비교 전 후보 축소 효과.
- 문서 간 ER — LLM이 SQL로 행을 샘플링·검사하고 정규화·정렬 SQL을 발행, 반복.
- PK 열이 free text거나 cardinality가 극단적이면 agent가 이 단계 스킵 가능.
Grouping. SQL GROUP BY pk로 분할. 각 그룹이 독립 reconciliation 단위.
4.5 Phase 2 세부 — Reconciliation Agent의 3가지 연산
Table 1. Executor agents for data reconciliation. 각 에이전트는 provenance와 rationale을 사용해 결정을 내리고 일관된 표현을 만듭니다.
| 연산 | Reconciliation Need | 결정 기준 | 액션 |
|---|---|---|---|
| Deduplication | 다른 표현으로 같거나 거의 같은 행이 있음 | provenance로 가장 정밀·명시적인 값을 선호 | 표준 표현을 선택, 중복 행 제거 |
| Conflict Resolution | 같은 속성에 대해 경쟁 값들이 존재 | provenance·rationale로 어느 값이 더 잘 지지되는지 판단 | 가장 잘 지지되는 값 보존, 양립 불가능 대안 제거 |
| Consolidation | 부분 행들이 같은 엔티티/사실의 상호 보완적 속성을 담음 | 모순 없이 결합 가능한지 판단 | 보완적 행들을 더 완전한 행으로 병합, 공유 값 전파 |
Evidence Integration. agent가 선택한 연산에 따라 SQL을 발행해 중간 쿼리(distinct count, 특정 컬럼 추출, 관련 행 조회)를 실행한 뒤 최종 update를 적용. 모든 reconciliation 행위가 SQL → 완전 감사 가능. 마지막으로 PK가 아닌 컬럼들에도 ER을 적용.
4.6 Question Answering — 반복적 SQL 합성
QA agent에는 (1) 스키마와 (2) 정합화된 DB가 주어집니다. 절차:
- agent가 SQL을 생성
- 결과 반환
- 필요하면 query를 수정 (스키마 탐색, 중간 집계 등)
- 만족할 때까지 반복
[Liu et al., 2024] 의 LLM+SQL 통합 추론 방식을 따릅니다.
5. 벤치마크 1 — 기존 Long-Context (≤ 360K 토큰)
먼저 base LM의 컨텍스트 윈도우에 들어가는 입력에서 SLIDERS가 chunk/reconciliation 오버헤드 대비 가치가 있는지를 검증합니다.
5.1 벤치마크 통계
Table 2. Benchmark statistics.
| Benchmark | # Docs | # Questions | Real/Synth | Task Type |
|---|---|---|---|---|
| FinanceBench [Islam 2023] | 1 per Q | 150 | Real | Extraction, Arithmetic |
| Loong [Wang 2024] | ~11 per Q | 50 | Real | Retrieval, Aggregation |
| Oolong [Bertsch 2025] | 1 per Q | 192 | Synthetic | Classification, Aggregation |
| WikiCeleb100 (new) | 100 | 22 | Real | Aggregation, Comparison |
| FinQ100 (new) | 100 | 25 | Real | Aggregation, Arithmetic |
- FinanceBench: 공적 재무공시 기반 단일 문서 QA, 150개 실세계 분석가 스타일 질문. LLM-as-a-judge로 정답·정답 근거·예측·예측 근거를 비교.
- Loong: 11개 문서가 모두 필요한 multi-doc QA. 4개 도메인 (English Finance, Chinese Finance, Chinese Legal, English Papers). Loong 공식 judge 사용.
- Oolong: aggregation 집중 long-context 벤치. 본 논문에서는 Oolong-Synth subset, 256K 컨텍스트에서 평가. 수치 질문은 편차 기반 점수, 비수치는 LLM-as-judge.
5.2 Baseline 셋업
| Baseline | 구성 |
|---|---|
| RAG | Qwen3-4B-Embedding + GPT-4.1, dense retrieval, 4096-token chunk, top-$k$=5 (Loong/Oolong) 또는 100 (FinQ100) |
| LongRAG [Jiang 2024] | 4K~30K 토큰 chunk로 그룹핑, reader는 GPT-4.1 |
| GraphRAG [Edge 2024] | corpus 위 knowledge graph + local search + GPT-4.1 |
| Base LM (GPT-4.1) | 동일 프롬프트·평가 프로토콜, 1M 토큰 윈도우 |
| Base LM (Qwen3.5 122B-A10B) | 오픈소스 frontier LM |
| DocETL [Shankar 2025] | V1 greedy optimizer, GPT-4.1, 16K-char chunking (SLIDERS와 동일), per-question 스키마, per-chunk map + single-pass reduce |
| Chain of Agents (CoA) [Zhang 2024] | 순차적으로 chunk별 running summary 갱신. GPT-4.1 synthesizer + GPT-4.1-mini summarizer |
| RLM [Zhang 2025] | Recursive LM. Python 프로그램으로 입력을 분해·재호출. 30 iterations, GPT-5 main + GPT-5-mini sub |
| SLIDERS | GPT-4.1 & GPT-4.1-mini 조합 또는 Qwen3.5 122B-A10B |
5.3 주요 결과
Table 3. Performance comparison across long document QA benchmarks. WC=WikiCeleb100, FQ=FinQ100. 두 ultra-long 벤치는 GPT-4.1 컨텍스트 한도 초과. RLM은 FinQ100 10문서에서 7.4% 기록, 전체 실행 추정 비용 $2000로 제외. 최고 결과 굵게. 최강 baseline 대비 paired t-test에서 모두 $p < 0.005$.
| “Long-Context” (<360k) | 3.9M T | 36M T | |||||
|---|---|---|---|---|---|---|---|
| Models | LLMs | FB | Loong | Oolong | Avg. | WC | FQ |
| RAG | Qwen3-4B & GPT-4.1 | 62.67 | 54.35 | 11.32 | 42.77 | 31.41 | 5.00 |
| LongRAG | Qwen3-4B & GPT-4.1 | 72.00 | 59.10 | 22.00 | 51.03 | 43.20 | 28.87 |
| GraphRAG | Qwen3-4B & GPT-4.1 | 75.33 | 61.28 | 22.00 | 52.87 | 48.59 | $$ |
| Base LM | GPT-4.1 | 82.00 | 76.74 | 45.56 | 68.69 | N.A. | N.A. |
| Base LM | Qwen3.5 122B-A10B | 84.67 | 74.78 | 24.89 | 61.44 | N.A. | N.A. |
| DocETL | GPT-4.1 | 63.33 | 75.03 | 49.00 | 62.44 | 54.26 | $$ |
| Chain of Agents | GPT-5 & GPT-5-mini | 71.30 | 54.46 | 17.11 | 47.62 | $$ | $$ |
| RLM | GPT-5 & GPT-5-mini | 75.33 | 72.64 | 51.42 | 66.46 | 59.80 | $$ |
| SLIDERS | GPT-4.1 & 4.1-mini | 89.33 | 78.57 | 64.67 | 75.56 | 78.91 | 55.22 |
| SLIDERS | Qwen3.5 122B-A10B | 82.10 | 75.70 | 68.00 | 75.26 | 76.92 | 60.18 |
관찰 1 — 컨텍스트에 들어가는데도 SLIDERS가 이긴다.
모든 입력이 GPT-4.1 컨텍스트에 들어가는데도 SLIDERS가 GPT-4.1 직접 대비 평균 +6.6pt. Oolong에서는 +19.1pt (aggregation 집중) 격차. 모든 벤치에서 $p < 0.005$로 통계적으로 유의. Loong 도메인별 — Chinese Legal 59.9, English Finance 74.8, Chinese Finance 89.2, English Papers 91.3. 단 Chinese Legal은 16K 짧은 분류 작업이라 chunking·reconciliation 오버헤드가 손해.
관찰 2 — Provenance가 감사성을 높이고 오류 분석을 돕는다.
오답 샘플링 시 provenance가 원인 파악(주관적 판단 미흡, 회계연도 vs 달력연도 같은 용어 오해)을 즉각 가능케 함. 또한 gold answer 자체에 오류(잘못된 값/단위, 다문서 결과 누락) 발견.
관찰 3 — 오픈소스 LLM에서도 효과는 그대로.
Qwen3.5-122B-A10B로도 평균 75.26 — 동일 모델을 base로 쓴 61.44 대비 +13.82pt. Oolong은 24.89 → 68.00 (+43pt)로 가장 큰 효과. SLIDERS의 효익은 모델 비종속적.
5.4 Ablation — 어떤 구성요소가 얼마나 기여하는가
220개 task 무작위 validation set.
Table 4. Ablation study (val set). 굵게/밑줄 = 1위/2위.
| Model | F. Bench | Loong | Oolong | Avg |
|---|---|---|---|---|
| SLIDERS | 80.00 | 84.37 | 64.67 | 74.79 |
| w/o Chunking | 70.00 | 79.72 | 40.00 | 60.34 |
| w/o Reconciliation | 76.70 | 82.84 | 62.42 | 72.71 |
| w/o Recon + SQL | 70.00 | 84.45 | 58.62 | 70.74 |
- Chunking이 모든 벤치, 특히 Oolong에 결정적 (없으면 40%로 급락)
- Reconciliation은 FinanceBench에서 특히 중요
- 추출 테이블을 LLM에 직접 답시키면 FinanceBench·Oolong 모두 큰 폭으로 하락 → SQL 추론 단계의 가치 입증
5.5 질문 유형별 성능 (Figure 4)
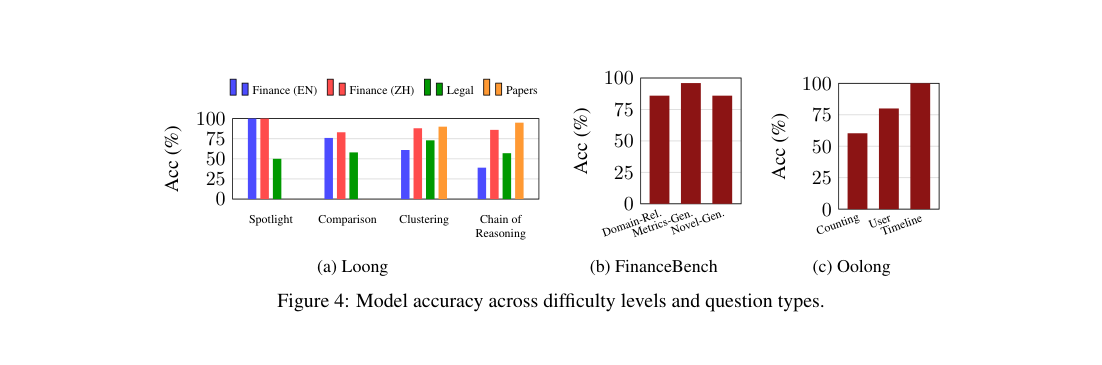
| 벤치 | 관찰 |
|---|---|
| Loong (Fig.4a) | 도메인 영향이 난이도보다 크다. ZH Finance·Papers는 모든 난이도에서 83% 이상. Legal은 73% 이하. Chain of Reasoning이 가장 어려움이나 도메인 의존적 — English Finance 39%, Papers 95%. |
| FinanceBench (Fig.4b) | 도메인 관련·신규·메트릭 생성 질문 모두에서 일관된 86~96%. |
| Oolong (Fig.4c) | User(80%) · Timeline(100%) · Counting(60.3%). Counting은 정확한 수치 출력 필요 — base LM의 추론·분류 능력에 의존하는 부분이며 SLIDERS 파이프라인 외부 병목. |
6. 벤치마크 2 — Ultra-Long (3.9M ~ 36M 토큰) · 본 논문의 새 기여
현 frontier LLM 컨텍스트를 초과하는 corpus에서 multi-doc aggregation을 스트레스 테스트하기 위해 두 벤치를 신규 공개. 하나의 corpus에 여러 질문을 던지는 실무 시나리오(분기보고서, 인물 DB 등)를 가정 — 추출·정합화는 1회, 질문마다 SQL만 새로 생성하므로 비용 분할 가능.
6.1 WikiCeleb100 — 3.9M 토큰, 위키 100건
- 2025년 11월 ~ 2026년 1월 기간 가장 조회된 셀럽 위키 100개. 3.9M 토큰.
- 22개 질문, 데뷔(debut) 주제. 대표 질문:
“Who debuted at the youngest age across the following industries: Music, Film, Content Creation, and Other?”
- 답하려면 100개 글에서 출생일·데뷔일·산업을 모두 추출해야 함.
- 한 번 추출된 schema는 “어느 10년대 출신 아티스트가 가장 많은가” 같은 후속 질문에도 재사용 가능.
6.2 FinQ100 — 36M 토큰, SEC 10-Q 100건
- 무작위 SEC 등록 기업 100개의 최신 10-Q. 36M 토큰.
- 25개 질문, 장기차입(long-term borrowing) 주제. 대표 질문:
“Which company has the lowest long-term borrowing?”
- 어려움 — 많은 기업이 장기차입금 0을 명시하지 않음. 컨텍스트로부터의 추론이 필수.
6.3 결과 (Table 3 우측 컬럼)
| 시스템 | WC (3.9M) | FQ (36M) | 비고 |
|---|---|---|---|
| RAG | 31.41 | 5.00 | — |
| LongRAG | 43.20 | 28.87 | — |
| GraphRAG | 48.59 | $$ | 인덱싱만 2.3시간, $182 |
| RLM | 59.80 | $$ (10문서 7.4%) | 전체 실행 $2000 추정 |
| SLIDERS (GPT-4.1) | 78.91 | 55.22 | 풀 실행 $34 (FinQ100) |
| SLIDERS (Qwen3.5) | 76.92 | 60.18 | 오픈소스 — FinQ100에서 더 좋음 |
관찰 1 — SOTA, 비용은 1/10 이하.
WikiCeleb100에서 78.9%로, 컨텍스트 한도 내 벤치와 거의 같은 정확도를 3.9M 토큰에서도 유지. RLM 대비 +19.1pt이면서 13배 비용 효율. FinQ100에서 55.2% — 같은 모델로 10문서 평가 시 RLM의 7.4% 대비 큰 격차. SLIDERS의 전체 FinQ100 비용은 $34 (RLM 전량 추정 $2000).
Reconciliation의 결정적 역할 — FinQ100은 답이 잘게 쪼개진 corpus: 추출은 685행을 만들지만 ground truth는 105행 (100개 기업). Ablation 결과:
| 벤치 | Reconciliation 사용 | 미사용 |
|---|---|---|
| FinQ100 | 55.22 | 35.81 |
| WikiCeleb100 | 78.91 | 60.50 |
관찰 2 — 자동화는 부족하지만 수작업을 가속.
FinQ100 55% 정확도는 고위험 금융 자동화에는 부족. 그러나 provenance 추적으로 사람 리뷰어가 추출을 빠르게 검증·수정 가능. 일단 DB가 검증되면 동일 corpus에 자유롭게 질문 가능 — SLIDERS가 즉시 SQL을 생성. 즉, human-in-the-loop 신뢰형 QA 플랫폼으로 작동.
7. 추가 분석
7.1 Input Context Length — 토큰 길이별 정확도 (Figure 5)
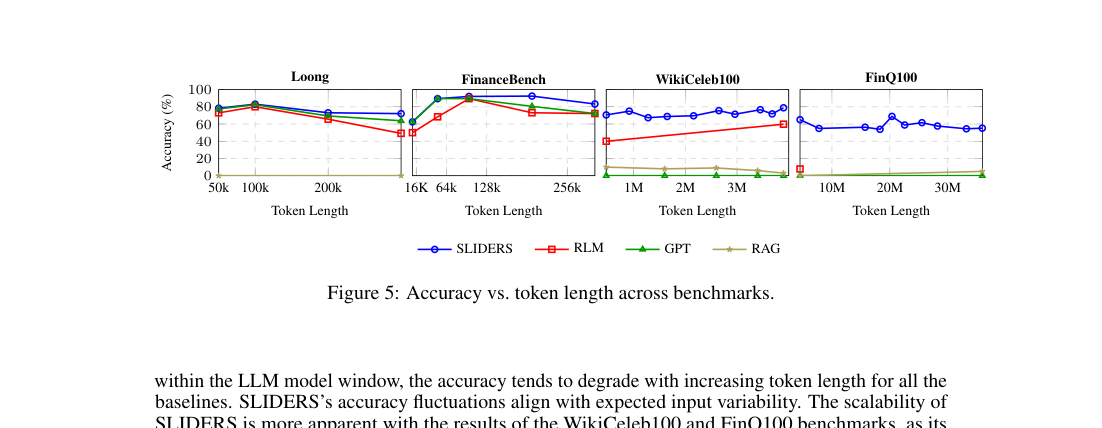
- 360K 이하 입력도 baseline은 토큰 길이가 늘면 정확도 하락
- SLIDERS는 입력 변동에 따른 fluctuation만 보임, 추세적 하락 없음
- WikiCeleb100·FinQ100에서 35M 토큰까지 일정 정확도 유지
- RLM은 4M까지 가능하나 낮은 정확도. 다른 baseline은 1M 이상 처리 불가
7.2 Schema Induction Robustness
Table 5. 스키마 유도 모델별 정확도 (max−min = ∆).
| Dataset | GPT-4.1 | GPT-4.1-mini | GPT-5 | ∆ |
|---|---|---|---|---|
| Loong Papers | 91.30 | 89.96 | 88.00 | 3.30 |
| Loong Legal | 64.12 | 68.34 | 61.26 | 7.08 |
| Loong Finance EN | 74.50 | 68.10 | 73.10 | 6.40 |
| Loong Finance ZH | 93.96 | 90.46 | 93.20 | 3.50 |
| Loong Avg | 80.97 | 79.22 | 78.89 | 2.08 |
| FinanceBench | 76.71 | 80.00 | 80.00 | 3.33 |
- GPT-4.1은 평균 1.0 테이블 · 3.3 필드. GPT-5는 1.54 테이블 · 13.3 필드 → 4배 복잡도 차이
- 그럼에도 Loong 평균 정확도는 단 2.1pt 차이, FinanceBench는 3.3pt 차이
- 결론: Schema Induction은 깨지기 쉬운 병목이 아님. 다만 너무 복잡한 schema는 reconciliation 난이도를 올려 한계 효용 체감.
7.3 Evaluation Reliability
LLM-as-a-judge 분산 — GPT-4.1 temperature 0.7로 3회 채점한 std:
| 벤치 | std |
|---|---|
| FinanceBench | 0.47 |
| Loong | 0.31 |
| Oolong | 1.02 |
| WikiCeleb | 0.21 |
| FinQ100 | 0.38 |
낮은 분산 → 평가 안정성.
수동 검증 (50 questions / dataset):
Table 6. Manual evaluation. FN/FP = false negative/positive vs human label.
| Dataset | System | Cohen’s κ | FN | FP |
|---|---|---|---|---|
| FinanceBench | SLIDERS | 0.769 | 4 | 0 |
| FinanceBench | GPT-4.1 | 0.646 | 3 | 2 |
| Oolong | SLIDERS | 0.855 | 1 | 1 |
| Combined | — | 0.758 | — | — |
- 종합 Cohen’s κ = 0.758 (substantial agreement)
- SLIDERS의 FinanceBench 오류는 모두 FN (4 FN, 0 FP) → 보고된 점수는 보수적 추정치
7.4 Cost — $0.76 / question 평균
- 약 40%가 Entity Resolution에 소요 (테이블 전체 스캔 필요)
- amortized 시나리오 (corpus 공유, 다회 질의)에서 진가 발휘
- WikiCeleb100: GPT-4.1 무한 컨텍스트로 풀 때 $171.60 → SLIDERS $13.10
- FinQ100: 동등 GPT-4.1 풀 비용 $1800 → SLIDERS $34.63
- RLM 대비 동등 이하 비용으로 더 높은 정확도 달성
7.5 Latency — 정확도가 우선인 워크플로
| 시나리오 | 측정 |
|---|---|
| End-to-end (cold) — Loong | 평균 2.6분 |
| End-to-end (cold) — FinanceBench | 평균 3.0분 |
| Amortized — 스키마 유도 | 20s |
| Amortized — 추출 (병렬) | 6분 (WikiCeleb100 전체) |
| Amortized — reconciliation | 9.7분 |
| Amortized — 질문당 SQL 생성 | ~25초 |
비교: GraphRAG는 동일 corpus 인덱싱에 2.3시간, $182, 정확도 48.59%. SLIDERS는 동일 corpus를 ~16분, $13에 처리하고 정확도 78.91%.
7.6 Case Study — Multi-Document Summarization
“Summarise the given research papers” 프롬프트로 Loong 3편의 ML 논문에 적용. agent가 자동으로 5-table schema를 유도:
PaperSummary(title, authors, abstract)PaperContributionsPaperMethodsPaperFindingsPaperConclusions
각각 paper_title로 linking key. 117 records 추출 후 논문별 일관된 요약으로 집계. chunk별 추출이라 컨텍스트 압박에 의한 정보 손실 없음. SLIDERS가 QA를 넘어 open-ended synthesis로 일반화 가능함을 보임.
8. Reconciliation Agent 심층 분석 (Figure 6)
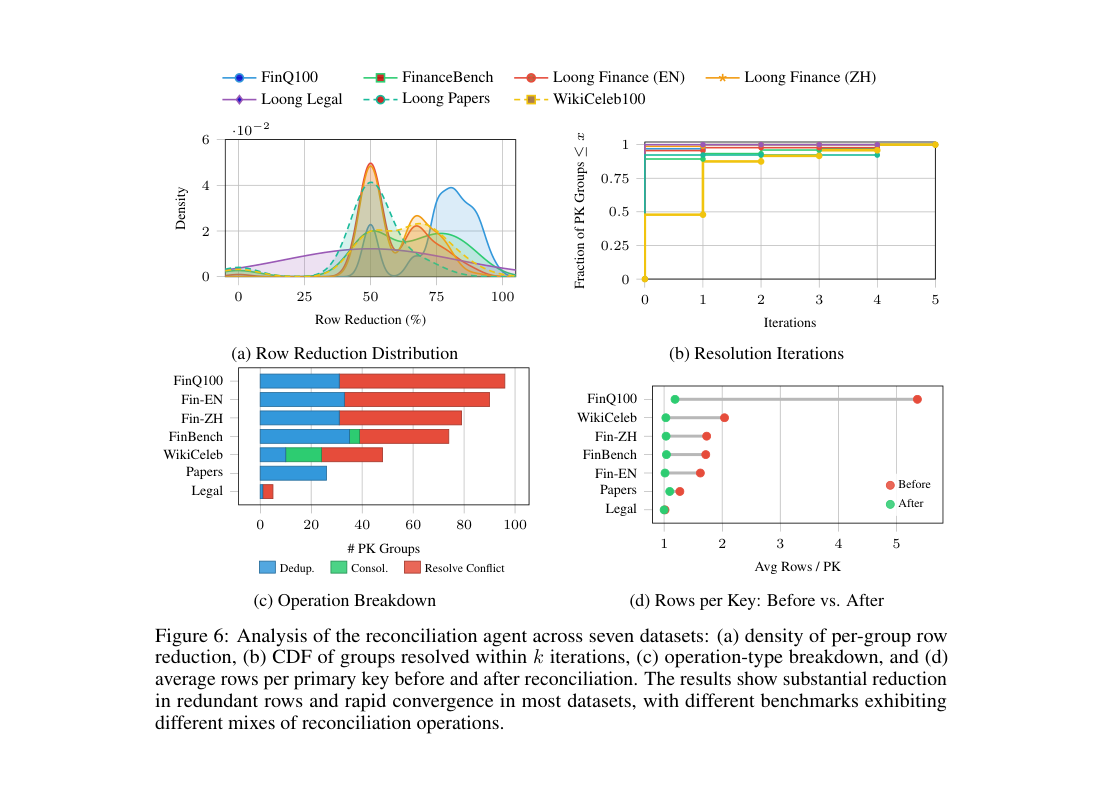
- (a) PK 그룹별 행 감소율 밀도
- (b) iteration $k$ 안에 해결된 PK 그룹의 CDF
- (c) Dedup / Consolidation / Conflict 의 연산 분포
- (d) PK당 평균 행 수 — reconciliation 전/후
규모 통계
| 코퍼스 | 평균 행 수 (추출) | 평균 PK 수 | 평균 행 수 (정합 후) |
|---|---|---|---|
| 기존 long-context 벤치(≤360k) | 10.25 | 7.22 | 7.48 |
| WikiCeleb100 | — | 101 | ~1 |
| FinQ100 | >5 / PK | 128 | ~1 |
행 감소 — 모든 코퍼스에서 PK당 평균 행 수가 1에 근접. FinQ100이 가장 강한 감소(70~90% 그룹), WikiCeleb100도 큰 폭. FinanceBench·Loong Finance는 중간, Loong Legal은 거의 변화 없음(chunk보다 짧은 문서).
연산 분포 (Fig 6c)
| 코퍼스 | 주된 연산 |
|---|---|
| FinQ100, Loong Finance | Conflict resolution 우세, 다음으로 Dedup. 같은 키에 경쟁 값이 많음 (provenance·rationale 비교 필요) |
| WikiCeleb100 | Dedup + Consolidation. 출처들이 일관되지만 상호 보완적 |
| FinanceBench | 양 극단의 중간, 약간의 Consolidation |
| Loong Papers | 거의 전부 Dedup |
| Loong Legal | 연산 거의 없음 |
수렴 속도 — 대부분 코퍼스에서 90% 이상의 그룹이 1 iteration에 해결. WikiCeleb100만 절반 정도가 1회에 끝나고 추가 패스 필요 (상호 보완적 증거의 반복 통합 때문). FinQ100은 행 수가 더 많은데도 수렴이 빠름 — duplicate/conflict 위주라 결정 1회로 끝나는 경우가 많기 때문. 평균 1.28 iteration / group.
Takeaway: Reconciliation은 단순 중복 제거를 넘어, 노이즈가 있는 국소 추출을 거의 정규형(PK당 1행) 인 글로벌 표현으로 변환. 동작 양상은 도메인에 따라 크게 다름 — 대형 금융 코퍼스는 충돌, 인물 위키는 합치기.
9. 핵심 기술 요약
SLIDERS 파이프라인 한 줄 요약
1
2
3
4
5
6
7
8
9
10
Documents D + Question q
→ (1) Chunking with metadata m^G, m^L
→ (2) Schema Induction S from q,M (with schema library)
→ (3) Structured Extraction per chunk via Relevance Gate
each cell = ⟨value, provenance, rationale⟩
→ (4) Data Reconciliation
Phase 1: Primary Key selection (majority of 3) + Entity Resolution + GROUP BY
Phase 2: per-group Agent loop {SELECT_OP → RECONCILE_SQL → APPLY}
ops = {Deduplication, Conflict Resolution, Consolidation}
→ (5) QA Agent generates SQL over reconciled DB, iterates
다섯 가지 핵심 아이디어
| # | 아이디어 | 효과 |
|---|---|---|
| 1 | 정보 표현 ↔ 추론 분리 — 비정형을 RDB로, 추론은 SQL로 | Aggregation Bottleneck 제거 |
| 2 | Aggregation을 결정적 연산으로 오프로드 | LLM의 약점(집계·산술) 회피 |
| 3 | Provenance·Rationale을 1급 시민으로 저장 | reconciliation 결정 근거 제공 + 감사 가능 |
| 4 | PK 기반 reconciliation 분할 | 행 수에 대한 quadratic 비용을 그룹 내부로 축소 |
| 5 | Schema Library + Relevance Gate | 일관된 정형 출력 + 환각 억제 (FN 0.4%) |
10. 의의 및 한계
의의
- 첫 provenance-aware reconciliation — LLM 정보 추출에서 출처·근거를 정합화의 1급 신호로 다룬 최초 시도
- 모델 비종속 효익 — Qwen3.5 오픈소스에서도 GPT-4.1 base 평균을 능가
- 실용적 ultra-long 스케일 — 36M 토큰까지 일정 정확도, baseline 대비 두 자릿수 pt 격차
- 감사 가능한 워크플로 — 모든 reconciliation 액션이 SQL → 사람 리뷰어가 직접 검증 가능, 99.03% 출처 정확도
한계
| # | 한계 | 권장 대응 |
|---|---|---|
| 1 | 관계형 모델링이 어려운 task (고도로 주관적/추상적 문서 간 추론)에서는 효익 제한 — 4× schema 복잡도 차이에도 정확도는 안정이지만, 모델링 자체가 안 되는 task는 별개 | 전·후처리 LLM 단계로 보강 |
| 2 | 다단계 LLM 호출로 end-to-end latency 2~3분 — real-time application 부적합 | accuracy-critical 비실시간 워크플로에 사용 |
| 3 | 평가가 LLM-as-judge 의존 — Cohen’s κ=0.758로 검증했으나 잔여 노이즈 존재 | 핵심 지표는 수동 검증 병행 |
| 4 | FinQ100 55% — 고위험 금융 완전 자동화에는 부족. provenance가 틀린 경우 reconciliation 결정도 흔들림 (410 facts 검증 중 99.03%만 정확) | human-in-the-loop 검증 워크플로로 배포 |
References
- Joshi, Shethia, Dao, Lam — Contexts are Never Long Enough (arXiv:2604.22294)
- SLIDERS Project Page (Stanford Genie)
- SLIDERS GitHub (stanford-oval/sliders)
- FinanceBench (Islam et al., 2023)
- Loong (Wang et al., 2024)
- Oolong (Bertsch et al., 2025) — arXiv:2511.02817
- LongRAG (Jiang et al., 2024)
- GraphRAG (Edge et al., 2024) — arXiv:2404.16130
- DocETL (Shankar et al., 2025)
- Chain of Agents (Zhang et al., 2024)
- Recursive Language Models (Zhang et al., 2025)